AI Agents for Market Research: Strategic Automation That Actually Holds Up
Market data moves faster than most teams can track. Competitors change pricing overnight, new features ship weekly, and customer sentiment swings with a single outage. Meanwhile, manual research still feels like the same old grind: expensive, slow, and hard to repeat.
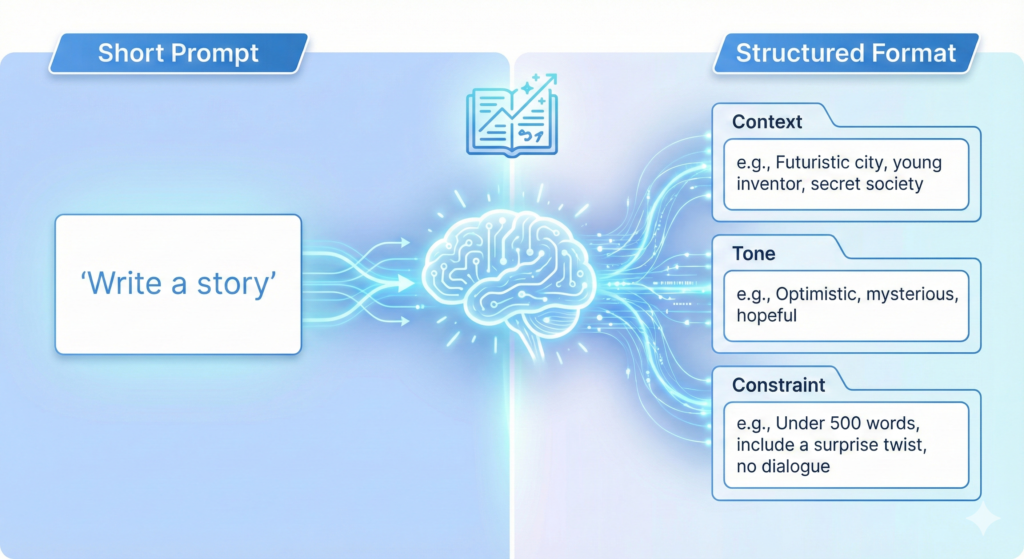
AI agents for market research solve a different problem than chatbots. An AI agent is software that can plan work, run tasks across tools, check results, then keep going until it hits a goal. That means fewer hours spent collecting screenshots and copying notes, and more time spent making decisions.
The payoff is real: quicker competitor insights, stronger trend detection, cleaner reports, and less busywork. Still, agents need guardrails. Use them to move faster, but keep humans on the hook for high-stakes calls.
What makes an AI agent different from a chatbot (and why it matters for research)
A chatbot answers questions you ask. An agent finishes a job you assign.
That shift matters because market research is rarely one question. It’s a workflow: find sources, collect evidence, normalize messy text, compare against last week, then write a brief that leadership can act on. If you’ve ever watched an analyst juggle 14 browser tabs, a spreadsheet, and a slide deck, you already understand why “just ask the model” isn’t enough.
In early 2026, the bigger story is reliability. Many teams are past the demo stage and now care about run-after-run consistency, logs, and failure modes. Recent industry reporting also points to a wide adoption gap: large spend on agents, but a much smaller share running them at scale, mostly because mistakes and security issues still show up in production.
The agent loop in plain English: observe, think, act, then double-check
A good research agent works in a loop:
- Observe: pull signals from approved sources (web pages, reviews, CRM notes, social posts).
- Think: decide what matters (pricing change vs. copy tweak), then plan steps.
- Act: run tasks like extracting tables, summarizing reviews, or clustering themes.
- Double-check: cite sources, verify numbers, and flag uncertainty.
That last step is where most “agent hype” falls apart. Without evaluation, you get confident summaries that may be wrong. With evaluation, you get a system that can say, “I found three sources, two disagree, so I’m marking this as unconfirmed.”
For a broader snapshot of current frameworks and how teams use them, see DataCamp’s overview of AI agents in 2026.
A simple architecture for a market research agent team
Most teams start small: one agent plus a few tools (browser, scraping, spreadsheet export). Later, they split responsibilities into a team.
Here’s a practical structure that holds up:
- Data connectors: web, app store reviews, Reddit, YouTube transcripts, newsletters, CRM, call transcripts.
- Planning agent: breaks the assignment into steps and schedules runs.
- Specialists: competitor agent, trends agent, sentiment agent, SEO research agent.
- Judge (QA) agent: checks citations, catches weird jumps in logic, and runs sanity checks.
- Reporting layer: sends alerts, updates dashboards, and drafts weekly briefs.
Frameworks like LangChain, CrewAI, and AutoGPT-style projects help orchestrate tools, but they’re not magic. Think of them as wiring. The real advantage comes from tight inputs, repeatable rubrics, and clear “stop conditions.” If you want a quick tour of what’s popular right now, this 2026 AI agent frameworks tier list gives helpful context.
High-impact workflows you can automate end-to-end with AI agents
The best workflows share one trait: humans hate doing them, but leaders still need the output. Agents shine when the work is repetitive, multi-source, and time-sensitive.
A realistic cadence is simple: daily monitoring for changes, weekly summaries for teams, and a monthly memo for leadership. In addition, many companies now run “risk scans” that watch supply chain or regulatory news, then alert procurement or ops when a vendor or region spikes in negative coverage.
If an agent can’t show where it got a claim, treat it like a rumor, not a finding.
Competitor gap analysis that updates itself every week
A competitor agent collects structured and unstructured signals, then compares them to your offer.
What it collects: pricing pages, feature lists, release notes, help docs, status pages, job posts, and key landing pages.
How often it runs: daily change detection, weekly synthesis.
What the output looks like: a “what changed” brief, plus a prioritized gap list mapped to your roadmap.
So what decision it supports: whether to adjust packaging, shift positioning, or fast-track a feature.
The best version doesn’t just say “Competitor X added SSO.” It tells you where, when, and what it might mean. For example, it can trigger an alert when a competitor changes tier names, rewrites their hero section, or adds enterprise language to SMB pages.
Trend spotting from many sources, not just one dashboard
Trend spotting fails when you only watch one channel. A research agent should scan across places where demand shows up early.
What it collects: niche forums, Reddit threads, product review sites, YouTube transcript summaries, newsletters, and news coverage.
How often it runs: light daily scans, deeper monthly scoring.
What the output looks like: a monthly trend memo with evidence links and representative quotes.
So what decision it supports: what to build next, what to stop building, and which vertical to target.
The key is separation: short-term noise vs. durable demand. Agents can score momentum by counting repeated themes across sources, then checking if the same theme appears in “money conversations” (pricing complaints, switching stories, procurement requirements).
If you’re building agent workflows for marketing teams, Vellum’s list of 2026 marketing agents is a useful menu of patterns you can adapt for research.
Social listening at scale, with sentiment you can trust
Sentiment is easy to compute and easy to get wrong. Agents can help, but only if you add quality checks.
What it collects: brand and competitor mentions, review text, support forums, and public social posts.
How often it runs: daily ingestion, weekly QA sampling.
What the output looks like: a sentiment dashboard plus 10 real quotes that explain the score.
So what decision it supports: which product pain to fix first, and which message to avoid.
Add a simple “trust layer”:
- Re-check a sample of labels each run and track false positives.
- Keep a “do not infer” list for sensitive topics (health, protected traits, personal identity).
- Tag sentiment by theme (price, reliability, integrations, support), not just positive or negative.
A “hidden intent” prompt library for market intelligence
Most research teams lose time because every analyst writes prompts differently. A shared library fixes that.
What it collects: the same source text you already have (reviews, calls, surveys), but with consistent interpretation prompts.
How often it runs: every time new text lands, with monthly prompt tuning.
What the output looks like: structured fields like buyer stage, switching trigger, objection type, and compliance needs.
So what decision it supports: sharper positioning, better sales enablement, and cleaner SEO topic selection.
A practical library includes prompts for:
- Buyer stage (curious, comparing, ready to buy, renewal risk)
- Switching triggers (price hike, outage, missing integration, security review)
- Objections (setup time, trust, vendor lock-in, reporting gaps)
- Compliance needs (SOC 2, HIPAA, data residency, audit logs)
Consistency matters because it lets you compare month to month without the “prompt drift” effect.
Synthetic users and simulated focus groups, when to use them and when not to
Synthetic users can speed early learning, especially when you’re still shaping positioning and don’t have enough interviews. They can also mislead you if you treat simulation like reality.
Use synthetic focus groups for idea pressure-testing, not for pricing validation or final messaging. They work best when you already have some real inputs, such as interview snippets, win-loss notes, and support tickets. Without that grounding, the agent will mirror your assumptions.
A simple way to explain it to stakeholders: synthetic users are like a flight simulator. Great for practice, but you still need a real test flight.
For research on agent evaluation and bias risks in decision contexts, the paper What Is Your AI Agent Buying? is a helpful reference point.
How to create persona-based agents to test messages and concepts
Persona agents should be built from your own evidence, not invented backstories.
Inputs that work well: ICP notes, actual interview quotes, onboarding feedback, support tickets, and churn reasons.
Outputs to ask for: reactions to landing pages, friction points on pricing pages, likely objections, and alternative positioning angles.
One rule keeps this honest: require the persona agent to cite the source snippets you fed it. If it can’t trace a claim to an input, it should label it as a hypothesis, not a “persona truth.”

Reducing bias, avoiding fake confidence, and validating with real data
Agents can amplify bias in two ways: they overfit to the docs you feed them, and they speak with calm confidence even when evidence is thin.
Safeguards that don’t slow you down:
- Compare synthetic insights to a small set of real interviews each month.
- Run a red-team prompt that tries to poke holes in the top recommendation.
- Use holdout checks (keep some data out, then test if the agent’s themes still appear).
- Label outputs clearly: synthetic insight vs. observed insight.
That labeling alone prevents bad meetings. Leaders stop treating simulated reactions as customer facts.
Turning agent outputs into an executive-ready research and SEO roadmap
Agent output becomes useful when it answers three questions: what changed, why it matters, and what we’re doing next. Otherwise, you just automated a messy inbox.
The strongest teams set a single reporting standard across product, marketing, and insights. They also pick one “system of record” for findings, such as a doc hub or research repository, so insights don’t disappear into Slack.
This is also where model choice comes in. Teams often use a stronger reasoning model (for example, GPT-4-class or Claude-class) for planning and QA, and a cheaper model for high-volume labeling. Open models (for example, Llama-class) can fit privacy needs when data can’t leave your environment.
Automating keyword clustering and topic maps without losing intent
Keyword clustering breaks when it ignores intent. Agents can help, but you need a workflow that starts with real language.
A solid pipeline looks like this:
- Collect queries from Search Console, competitor pages, and customer wording from reviews and calls.
- Cluster by intent, not by shared words.
- Label each cluster with a plain-English promise (what the searcher wants to achieve).
- Map clusters to funnel stage, then draft one content brief per cluster.
Quality checks matter here. Remove near-duplicates, separate brand terms, and spot clusters that don’t match actual SERP patterns.
From raw signals to a one-page plan: priorities, owners, and timelines
To keep decisions clean, use a simple scoring model before you ship work to teams. This table is easy to reuse in a monthly review.
| Factor | What it means | Score (1 to 5) |
|---|---|---|
| Impact | Revenue, retention, pipeline, or risk reduction | |
| Effort | Engineering or content time required | |
| Confidence | Strength of evidence and source agreement | |
| Time sensitivity | Competitor move, launch window, or news cycle |
After scoring, convert the top items into three deliverables: weekly alerts (changes and risks), a monthly insight report (themes and evidence), and a quarterly roadmap (bets with owners).
Assign clear owners: marketing for content and positioning, product for feature gaps, sales for objections and enablement. Track outcomes with a short set of metrics, such as traffic, conversion rate, churn drivers, and win rate.

Guardrails that keep agents safe and credible
Agent failures are rarely mysterious. They come from weak boundaries.
Put these in place early:
- Source citations for every claim that might influence spend or strategy.
- “Show your work” requirements (what sources were used, what changed since last run).
- Rate limits and domain allowlists for web actions.
- Approval gates for external actions (posting, emailing, purchasing).
- Full logging so you can replay decisions.
Also plan for common threats. Prompt injection can sneak instructions into scraped pages. Data leakage can happen when proprietary notes get pasted into the wrong system. Human review should be mandatory for pricing moves, legal topics, and any recommendation with major budget impact.
FAQ (Readers Asked Questions Frequently)
Are AI agents for market research worth it for small teams?
Yes, if you start with one workflow that saves hours weekly, such as competitor change alerts. Avoid building a “do everything” system first.
What’s the safest first use case?
Monitoring public competitor pages and summarizing changes is low-risk, because the sources are visible and easy to verify.
Do agents replace surveys and interviews?
No. Agents speed collection and synthesis. You still need real customer conversations for truth and nuance.
How do I stop hallucinations from entering a report?
Require citations, run a QA agent that checks quotes and numbers, and block “uncited claims” from the final brief.
What tools do I need to get started?
A model, a browser or scraping tool, a place to store sources, and a report template. Frameworks can help later, but process matters more than tooling.

Conclusion
If market data feels like a moving train, agents are how you stop sprinting beside it. Start with one workflow, either competitor change tracking or a monthly trend memo. Define inputs, success criteria, and QA checks, then expand into a small agent team with a judge step.
Next, turn outputs into action with a one-page plan and clear owners. With the right guardrails, AI agents for market research won’t just automate busywork, they’ll improve how fast your team learns.
Download the AI Research Agent Architecture Diagram, grab the Python starter script for a basic competitor analysis agent, and use the hidden intent prompt pack to standardize insights across teams.














 Photo by
Photo by