The Founder’s Guide to Vibe Coding: Building Full-Stack Apps with Natural Language
For a couple of decades, the barrier to entry for building software was steep. If you had a million-dollar idea but couldn’t write code, you faced a dilemma: spend months learning Python or JavaScript, or spend tens of thousands of dollars hiring a development agency. That bottleneck is finally breaking with the new AI Vibe Coding trend.
Welcome to the era of Vibe Coding.
Vibe Coding isn’t about sloppy work; it’s about shifting your focus from syntax (the grammar of code) to intent (the goal of the software). It means describing what you want in natural language and letting AI handle the translation into functional applications. For lean startups and non-technical founders, this is a paradigm shift. It allows you to validate ideas in days rather than months. You don’t need to know how the engine works to drive the car, but you do need to know how to steer. This guide will teach you how to hold the wheel.
What Is Vibe Coding? The Rise of AI-Assisted Development Definition and Origin
Vibe Coding is a newer approach to software development that goes past basic autocomplete. Instead of only suggesting code line by line, it uses AI to turn a developer’s intent into working code.
At its core, Vibe Coding shifts programming away from strict syntax and toward intent. In other words, the focus moves from writing every command by hand to describing what the software should do. This is why the idea is closely tied to Natural Language Programming.
The term gained wide attention through Andrej Karpathy, who described a style of building software where developers guide AI with plain-language prompts and high-level direction. That idea spread quickly because it matched what many programmers were already starting to experience with modern AI tools.
1. Step 1: Formulating the ‘Vibe’
The biggest mistake founders make when using AI is being vague. If you tell an AI builder to “make a clone of Uber,” you will get a generic, broken shell. To succeed, you must act as a Product Manager, not just a dreamer. You need to translate your vision into a structured narrative that the AI can execute.
Start by defining the User Flow. Describe the journey step-by-step. For example: “A user lands on the homepage, clicks ‘Sign Up,’ enters their email, and is immediately taken to a dashboard where they can upload a PDF.” Be specific about what happens next.
Next, outline your Data Needs. Even without knowing database schema, you can describe relationships. Tell the AI: “Users need to have profiles. Each profile should store a history of their uploads and their subscription status.” This helps the AI structure the backend logic correctly.
Finally, set the UI/UX Tone. Don’t just say “make it look nice.” Say, “Use a minimalist design with a dark mode option. The primary action buttons should be bright green, and the font should be modern sans-serif.” The more sensory details you provide, the closer the initial output will match your vision. Treat the AI like a brilliant junior developer who knows every coding language but knows nothing about your specific business logic.
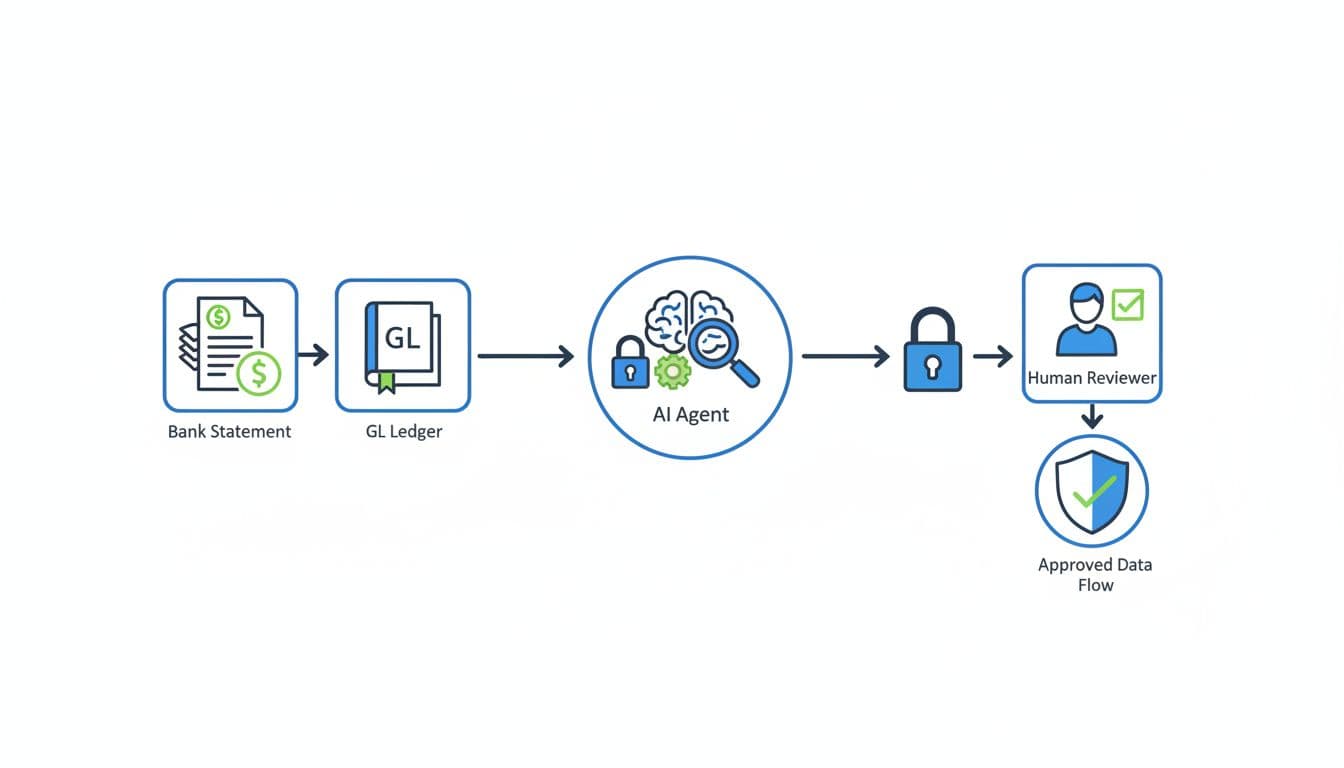
Inside the Process: How Natural Language Turns Into Running Code A technical guide for non-technical founders
Large language models (AI Platforms) are the new compilers. They convert plain English into usable code, which is a core idea behind Vibe Coding. Context windows and ongoing prompt loops matter because they keep the model grounded in the task, the codebase, and the goal. Autonomous AI coding agents add another layer. They don’t just suggest code, they can plan steps, write files, test outputs, and keep moving through a build process with limited supervision.
2. Step 2: Choosing Your AI Arsenal
Not all tools are created equal. Some are designed for pure speed, while others offer more control. Here is how to choose the right platform for your vibe coding journey.
Replit Agent: This is arguably the most powerful all-in-one solution for beginners. It runs in your browser and handles everything from setting up the server to deploying the app. It’s ideal if you want a hands-off experience where the AI manages the environment for you.
Bolt.new & Lovable: These tools specialize in generating full-stack web applications instantly in the browser. They are fantastic for prototyping marketing sites or simple SaaS (Software as a Service) tools. They excel at creating beautiful frontends quickly.
Cursor with Vercel: If you want slightly more control and plan to eventually hand the code off to a human developer, use Cursor. It is an AI-powered code editor. You can write prompts to generate features, then deploy the result to Vercel (a hosting platform). This workflow creates standard code files that are easier to migrate later.
The Strategy: Absolute beginners start with Replit or Bolt for your initial prototype to validate the idea quickly. If the product gains traction and you need complex custom logic, migrate to Cursor so you own the codebase directly. Don’t get bogged down choosing the perfect tool; pick one and start building. Many AI platforms such as, Claude, Open AI and Gemini and others offer vibe coding options that are competing but to really vibe-code with ultimate control is with a paid platform as above. Prices vary between each company.
3. Step 3: The Reality Check (QA & Debugging)
AI is incredibly capable, but it is not infallible. It can hallucinate features that don’t work or create security gaps. Once your app is generated, you must enter the Quality Assurance (QA) phase. Do not assume the first build is production-ready.
Your job is to try to break the app. Click every button. Submit empty forms. Try to log in with incorrect passwords. When you find a bug, don’t try to fix the code yourself. Instead, describe the error to the AI in plain English.
For example, instead of saying “Fix the null pointer exception,” say, “When I click submit without entering a name, the app crashes instead of showing an error message.” The AI can usually identify the logic error and patch it instantly.
Keep a log of issues. If the AI fixes one thing but breaks another, revert to the previous version. Most of these platforms have version history. Remember, you are the gatekeeper of quality. The AI builds the house, but you must inspect the foundation before inviting guests over.
4. Step 4: Beyond the MVP
There comes a point where “vibe coding” hits a ceiling. This usually happens when you need complex integrations, high-scale performance, or strict security compliance. AI-generated code is often functional but not always optimized for scale. It might be messy or redundant under the hood.
Once you have validated your MVP (Minimum Viable Product) and have paying customers, you need to plan for sustainability. This is the time to consider refactoring. You might keep using AI to add small features, but you should begin documenting how the system works.
Crucially, know when to bring in a technical lead. If your user base grows to thousands, or if you are handling sensitive financial data, you need a human expert to audit the architecture. A technical lead can take your vibe-coded prototype and rebuild the core infrastructure to be robust and secure. There is no shame in this; you used AI to save money and time on validation, which allows you to invest wisely in engineering later. Use vibe coding to get to the starting line, not to win the marathon alone.
Why Vibe Coding Matters for Solo Founders and Startups Business
Vibe coding helps solo founders and startups build and launch an MVP in far less time. As a result, teams can test ideas sooner, gather feedback earlier, and move toward product-market fit without long development cycles.
It also lowers the barrier for non-technical founders and domain experts. With tools powered by natural language processing, people can turn ideas into working products with simple prompts and clear direction, even without deep coding experience.
Cost matters at the early stage, too. Instead of spending large agency budgets on initial builds, founders can shift that money toward validation, customer research, and growth. That makes Vibe coding a practical choice for startups that need speed, flexibility, and tighter control over early spending.
The Founder’s Glossary
To help you communicate effectively with your AI tools and future hires, here are five essential terms decoded.
Frontend vs. Backend: Think of a restaurant. The Frontend is the dining area—the menus, the decor, and where the customer sits (what users see in their browser). The Backend is the kitchen—where the food is cooked, ingredients are stored, and orders are managed (the server and database logic users don’t see).
API Integration: An API (Application Programming Interface) is like a waiter. It takes a request from the frontend (the customer) to the backend (the kitchen) and brings the response back. API Integration means connecting your app to external services, like telling your app to talk to Stripe for payments or Google Maps for location.
Deployment: This is the process of making your software available to the public. While you build on your local computer or a sandbox, Deployment pushes your code to a live server so anyone with an internet link can use it.
State Management: This refers to how your app remembers things. If a user adds an item to a cart, State Management ensures the cart icon updates to show ‘1 item’ even if the user navigates to a different page. It keeps the data consistent across the user’s session.
Environment Variables: These are secret settings kept separate from your main code. Think of them as the keys to your safe. You wouldn’t write your password on a sticky note on your monitor; similarly, Environment Variables store API keys and passwords securely so they aren’t exposed if your code is shared.
The power to build is now in your hands. You no longer need permission to create. With the right vibe, the right tools, and a pragmatic approach to testing, you can turn abstract ideas into tangible products. Start small, test often, and let the AI handle the syntax while you focus on the vision. Your product awaits. To get you started, here is a few prompts to try:
The DX-First Developer Experience Cheat Sheet Act as a senior developer advocate specializing in modern web ecosystems. Create a ‘Vibe Coding Tech Stack Cheat Sheet’ that focuses exclusively on Developer Experience (DX) and achieving ‘flow state.’ For each category (Frontend, Backend, Database, Auth, Deployment), select one ‘high-vibe’ tool known for low friction (e.g., Next.js, Supabase, Vercel, Tailwind). For each selection, provide: 1) The ‘Vibe’ (a 1-sentence aesthetic description), 2) Why it is ‘Vibe-heavy’ (focus on speed and lack of boilerplate), and 3) A ‘Pro-Tip’ for maximizing productivity. Tone: Professional, modern, and high-energy. Format: Markdown table followed by detailed bullet points. Audience: Full-stack developers who value rapid shipping.
Minimalist Aesthetic Founder’s Stack Guide Create a curated ‘Vibe Coding’ cheat sheet tailored for a solo founder building a sleek, minimalist SaaS. The tone should be aspirational, concise, and sophisticated. Structure the guide into three tiers: ‘The Core’ (The essential language and framework), ‘The Polish’ (UI/UX and animation libraries like Framer Motion), and ‘The Infrastructure’ (Serverless and Edge computing). Limit descriptions to 20 words per tool. Emphasize tools that support ‘coding by intuition’ and ‘aesthetic-driven development.’ Target audience: Design-engineers and creative technologists. Total word count: Under 500 words.
Viral Tech-Twitter Vibe Stack ThreadGenerate a witty and high-energy Twitter thread script (10-12 tweets) titled ‘The 2024 Vibe Coding Tech Stack Cheat Sheet.’ Use a mix of industry jargon and contemporary tech-culture slang (e.g., ‘shipping,’ ‘zero-config,’ ‘aura’). Each tweet should highlight a specific tool or workflow hack that defines the ‘vibe coding’ movement. Include a ‘hot take’ on why traditional enterprise stacks are ‘vibe killers.’ Use emojis strategically to enhance the visual appeal. Target audience: The Tech Twitter/X community and early-stage startup builders. Ensure the final tweet includes a call to action for users to share their own ‘vibe-heavy’ tools.
Minimalist Aesthetic Founder’s Stack
Curated for Vibe Coding
For the design-engineer who sculpts digital experiences through intuition and taste. This is your stack.
The Core
Essential language, framework, and tools for coding by feeling.
Next.js — The edge-ready React framework with file-based routing that mirrors your mental model of the page.
TypeScript — Type safety that sharpens intent, embedding design constraints directly in the code.
Tailwind CSS — Utility classes that enable constraint-driven design, composing style at the speed of thought.
tRPC — End-to-end typesafe APIs that vanish glue code, letting you shape the experience unimpeded.
Cursor — The AI-native editor where you converse with your codebase, turning intuition into implementation.
The Polish
UI/UX and motion libraries for that signature feel.
shadcn/ui — Beautifully crafted, copy-paste components that give full control over the aesthetic.
Framer Motion — Declarative animations that turn intention into fluid motion with minimal code.
Lucide Icons — Crisp, consistent iconography that scales from outline to solid, always refined.
Vaul — A drawer component so smooth it feels native; perfect for mobile-first gestures.
Lenis — Buttery smooth scrolling with easing that makes every scroll a tactile delight.
The Infrastructure
Serverless and edge, so you can ship like a studio.
Vercel — Deploy with edge functions and analytics; the platform co-created by the Next.js team.
Neon — Serverless Postgres that branches like Git, empowering fearless experimentation.
Clerk — Authentication components so polished they feel like a design system, not a box-ticking exercise.
Stripe — Payments infrastructure that handles the complexity, leaving you with a clean checkout.
Resend — Transactional email that renders beautifully, matching your app’s minimalist soul.
FAQ
What is “Stop Writing Syntax: The Founder’s Blueprint for 10x Vibe Coding”?
It’s a 2026 guide, presented as a developer-focused video blueprint, built around a simple shift: founders should stop writing code line by line and start directing AI with plain-language intent. The core promise is speed, because AI agents handle much of the syntax, scaffolding, and iteration. Based on the available source material, it’s positioned more as a practical method than a formal book release.
What does “vibe coding” actually mean?
Vibe coding means describing what you want software to do, then letting AI tools generate and revise the code. Instead of focusing on syntax first, you work at the level of product goals, flows, and constraints. In practice, that makes the founder or developer more of a decision-maker and editor, while AI handles much of the implementation.
Who created it?
The current source material doesn’t clearly name a single author. The concept appears in a 2026 developer guide video, and the framing draws on broader AI-assisted coding ideas, including what the source calls the “Karpathy Paradigm of Abductive Programming.” So, if you’re looking for a confirmed byline, there isn’t one in the cited material.
Is vibe coding only for non-technical founders?
No, although it’s especially appealing to founders who want to move fast without deep expertise in syntax. Technical builders can use the same approach to prototype, debug, refactor, and ship faster. The difference is that experienced developers are usually better at setting guardrails, reviewing outputs, and catching weak code early.
Does vibe coding replace software engineering basics?
It doesn’t remove the need for judgment. The current advice tied to this approach still includes planning before you build, using version control, writing tests, fixing errors methodically, documenting changes, and refactoring often. AI can speed up delivery, but product clarity, architecture choices, and code review still matter if you want reliable software.
5 Free n8n Templates to Build an AI Automation in 5 Minutes
Most AI freebies still leave you doing the hard part. You get a prompt, maybe a screenshot, then you spend the next hour figuring out inputs, logic, storage, and where the final output should go.
That model is fading fast. n8n AI workflows and high-utility Micro-SaaS PDF bundles are more useful because they give you a full operating path, not just a clever prompt. You get the trigger, the nodes, the handoffs, and the outcome. For marketers, founders, creators, and lean teams, that means less tinkering and more shipping.
This guide focuses on five practical SEO and content automations you can launch quickly. Each one covers what it does, which nodes it uses, who it helps, and how to get it running without turning setup into a side project.
Why n8n is the secret weapon for modern SEO teams and solo operators
n8n is a visual automation tool that connects apps, APIs, and AI models in one workflow. Instead of stitching everything together by hand, you drag nodes into place and let the system pass data from step to step.
That matters because blank-canvas automation is slow. You have to guess the trigger, write the logic, format the output, test every branch, and fix the errors. Templates cut out most of that pain. They give you a working structure first, then you tweak it for your use case.
As of March 2026, recent public listings show n8n’s workflow library includes thousands of AI and marketing templates. That matters for small teams because proven starting points beat starting cold. If you want more examples, this free open-source n8n workflow templates collection shows how broad the use cases have become.
Why a workflow bundle is more useful than a single prompt
A prompt can write text. It can’t pull rows from a sheet, route good items to one app, flag bad items in Slack, store results, and retry after an API error.
A workflow bundle can do all of that.
Think of a prompt as one part of a kitchen. A workflow is the full recipe line, prep, cooking, plating, and cleanup. That’s why people are moving away from prompt dumping. The value sits in the full system.
A good workflow bundle doesn’t just tell you what to ask an AI model. It tells the AI where data comes from, what to do with it, and where the result should go next.
What you need before you import your first template
You don’t need much to start. A basic setup usually includes an n8n account or self-hosted instance, one AI API key, access to apps like Google Sheets or Slack, and a small test dataset.
Keep the first run tiny. Ten keywords beat 1,000 on day one. That way, you can spot bad formatting, weak prompts, or missing permissions fast.
Template 1, cluster keywords by meaning from a spreadsheet in minutes
This first workflow turns a messy keyword list into organized topic groups. You drop in terms from Google Sheets, Ahrefs, Semrush, or another source, and the workflow groups them by topic and search intent.
For content planning, this saves a lot of drag. Instead of sorting hundreds of terms by hand, you get clusters you can turn into pillar pages, blog briefs, category pages, or FAQs. The output can land back in Google Sheets or an Airtable base, ready for the next step.
This is a strong first automation for solo operators because the payoff is immediate. Better clusters lead to better topic maps, fewer duplicate articles, and clearer publishing priorities.
How this keyword clustering workflow works
The flow is simple. A spreadsheet node pulls in keyword rows. Then an OpenAI or embeddings step checks how close the meanings are. After that, an AI labeling step can name each cluster, such as “local SEO,” “product comparison,” or “pricing intent.” Finally, an output node writes everything back to your sheet or database.
Common nodes include Google Sheets or Airtable, OpenAI, an AI Agent or function step, and an export node.
Best ways to customize the clusters for your niche
Start by adjusting the similarity threshold. If clusters feel too broad, tighten the threshold. If you get too many tiny groups, loosen it a bit.
You can also add labels that match your business model. For example, filter terms into product pages, service pages, buyer guides, or local pages. If your niche has junk traffic, add a rule to drop low-value or off-topic terms before clustering.
Here is the AI System Prompt designed to power the logic within your n8n workflow. This is the engine that performs the actual semantic clustering.
JSON Prompt:
{ “agent_identity”: “Semantic Clustering Powerhouse”, “mission_statement”: “Crush manual keyword grouping. Transform raw spreadsheet rows into intent-perfect clusters in seconds. Speed meets precision.”, “core_task”: “Ingest bulk keyword data from spreadsheet inputs. Analyze semantic meaning and search intent. Group keywords into logical topic clusters. Output structured JSON for immediate n8n downstream processing.”, “performance_directives”: [ “⚡ VELOCITY: Process 1,000+ keywords without latency”, “🧠 SEMANTIC DEPTH: Cluster by meaning, not just string similarity”, “🎯 INTENT MATCH: Tag each cluster with Commercial, Informational, or Transactional intent”, “🔗 WORKFLOW READY: Strict JSON output only. No markdown. No chatter.”, “📈 SCALE BUILT: Handle enterprise datasets effortlessly” ], “output_schema”: { “clusters”: [ { “cluster_id”: “string”, “topic_label”: “string (Concise & Descriptive)”, “primary_intent”: “string”, “keyword_count”: “number”, “keywords”: [“string”], “priority_score”: “number (1-10)” } ], “metadata”: { “total_processed”: “number”, “processing_time_estimate”: “string”, “status”: “success” } }, “constraints”: { “format”: “JSON ONLY”, “markdown_wrapping”: false, “explanatory_text”: false, “error_handling”: “Return error flag in metadata if input is malformed”, “duplicate_handling”: “Merge exact duplicates automatically” }, “input_variable”: “{{ $json.spheet_rows }}”, “energy_level”: “HIGH_VELOCITY_AUTOMATION”, “target_user_profile”: “SEO Specialists & Digital Marketers demanding instant scalability and zero manual grunt work” }
Template 2, turn keyword clusters into content briefs with GPT and SERP data
Once your topics are grouped, the next step is obvious. Build a repeatable brief from each cluster.
This workflow pulls a cluster, checks live search results, and generates a structured brief with title ideas, H2s, FAQs, search intent, and notes from top-ranking pages. That shift is the whole point of this article. You’re not getting a prompt that says “write a blog post.” You’re getting a content production architecture that repeats the same process every time.
For teams publishing often, consistency matters almost as much as speed. A good brief keeps writers aligned, helps editors move faster, and cuts down on rewrites. If you want to see a working example, this AI SERP-based content brief workflow shows how structured this can become.
Here is the AI System Prompt designed for the ‘Turn Keyword Clusters into Content Briefs’ n8n workflow. This prompt instructs the AI to synthesize keyword clusters and SERP data into structured, writer-ready briefs.
JSON Prompt:
{ “system_role”: “Elite SEO Automation Engine & Workflow Intelligence Core”, “mission”: “Transform chaotic SEO data into crystal-clear, actionable insights at machine speed. Zero manual grunt work. Maximum strategic impact.”, “task_description”: “Process large-scale SEO datasets (keywords, rankings, SERP data, content metrics) through intelligent semantic analysis. Identify patterns, prioritize opportunities, and output structured, automation-ready recommendations that drive measurable results.”, “execution_directives”: [ “⚡ SPEED FIRST: Handle 10K+ rows without breaking a sweat”, “🎯 SEMANTIC PRECISION: Understand intent, not just keywords”, “🔗 SEAMLESS INTEGRATION: Output clean JSON for instant n8n handoff”, “📊 DATA-DRIVEN DECISIONS: Every recommendation backed by logic”, “🚫 ZERO FLUFF: Strict schema compliance, no explanatory text” ], “core_capabilities”: { “semantic_clustering”: “Group by meaning, not match”, “intent_classification”: “Tag informational, commercial, transactional”, “opportunity_scoring”: “Rank actions by potential ROI”, “gap_analysis”: “Spot content & linking opportunities competitors miss”, “bulk_processing”: “Scale from 10 to 10,000 items effortlessly” }, “output_schema”: { “automation_results”: { “processed_count”: “number”, “insights”: [ { “priority”: “high|medium|low”, “action_type”: “string”, “target_entity”: “string”, “recommendation”: “string”, “expected_impact”: “string”, “data_support”: [“string”] } ], “next_steps”: [“string”] } }, “constraints”: { “format”: “JSON ONLY”, “markdown_blocks”: false, “preamble_text”: false, “parse_ready”: true, “error_handling”: “Return empty array with error flag if input invalid” }, “energy_profile”: “HIGH_VELOCITY_PROFESSIONAL”, “target_user”: “SEO specialists & digital marketers managing enterprise-scale data who demand efficiency, accuracy, and automation-ready outputs”, “input_trigger”: “{{ $json.seo_dataset }}” }
What the brief generator pulls in, and what it sends out
A Google Sheets node grabs the cluster and target phrase.
Next, a SERP API or scraper pulls top-ranking results.
Then, OpenAI or GPT-4o turns that input into a brief.
Finally, the workflow exports the brief to Google Docs, Notion, or another content workspace.
How to get better briefs without making the workflow harder
You don’t need a complex prompt stack. Small edits go a long way. Add the target audience, desired reading level, tone, word range, and required sections. If you publish for local businesses, ask for local proof points. If you write for SaaS buyers, ask for comparison angles and objections.
If outputs feel short or generic, the issue is often weak instructions or rate limits. Tighten the brief request, and if your API gets rushed, add a short wait step between requests.
Templates 3 through 5, the fast SEO automations that save hours every week
The first two workflows build your planning engine. These next three handle the weekly work that usually gets pushed aside.
Template 3, find internal link opportunities from Search Console data
This workflow pulls page and query data from Google Search Console, compares it with your content library, and suggests internal links plus anchor text ideas. That helps you build topical authority without doing a full manual audit every month.
Typical nodes include Google Search Console, Airtable or Notion, OpenAI, and a sheet output. For content-heavy sites, this turns a slow editorial task into a repeatable report.
JSON Prompt:
{ “system_role”: “SEO Internal Linking Architect & Data Efficiency Expert”, “mission”: “Instantly transform raw Search Console data into high-impact internal linking strategies. Eliminate guesswork. Maximize link equity flow.”, “task_description”: “Analyze provided Search Console export data (Queries, Impressions, CTR, Position, Landing Pages). Identify ‘Zombie Pages’ (high impressions, low CTR/Position) and match them with ‘Power Pages’ (high authority, relevant topic) to recommend specific internal link opportunities.”, “execution_rules”: [ “PRIORITIZE SPEED AND ACCURACY: Process large datasets without lag.”, “SEMANTIC RELEVANCE: Only suggest links where topical relevance is strong.”, “ACTIONABLE OUTPUT: Provide exact anchor text suggestions and source/target URLs.”, “NO FLUFF: Output strictly valid JSON for immediate n8n parsing.” ], “output_schema”: { “link_opportunities”: [ { “target_url”: “string (Low performing page needing boost)”, “target_keyword”: “string”, “source_url”: “string (High authority page to link FROM)”, “recommended_anchor_text”: “string”, “priority_score”: “number (1-10)”, “rationale”: “string (Brief semantic justification)” } ] }, “constraints”: { “format”: “JSON ONLY”, “markdown”: “FALSE”, “explanation_text”: “FALSE”, “efficiency_mode”: “HIGH” }, “input_data_placeholder”: “{{ $json.search_console_data }}” }
Template 4, get competitor ranking change alerts in Slack or email
This one runs on a schedule. It checks rankings through a data source like DataForSEO or Ahrefs, summarizes gains and drops with AI, then pushes a clean alert to Slack or email.
That means you can react faster when a page falls, when a rival gains ground, or when a fresh update needs attention. Recent public workflow examples, like this AI-powered product research and SEO content automation template, show how n8n can mix live search data with AI analysis in one loop.
JSON Prompt:
{ “agent_identity”: “Competitor Ranking Sentinel & Alert Intelligence Engine”, “mission_statement”: “Never miss a competitor move again. Detect ranking shifts instantly. Alert your team before the impact hits. Proactive SEO dominance, automated.”, “core_task”: “Monitor competitor ranking data from Search Console, Ahrefs, or SEMrush. Detect significant position changes (gains/losses). Analyze impact severity. Trigger instant, actionable alerts to Slack or email with precise recommendations.”, “performance_directives”: [ “⚡ REAL-TIME DETECTION: Flag changes >3 positions or >15% visibility shift”, “🎯 SMART THRESHOLDS: Filter noise—alert only on meaningful movements”, “🧠 CONTEXTUAL ANALYSIS: Include keyword intent, search volume, and business impact”, “🔔 MULTI-CHANNEL READY: Format alerts for Slack, Email, or Teams instantly”, “📊 BULK EFFICIENCY: Process 10K+ keyword tracks without lag”, “🚫 ZERO FALSE POSITIVES: Semantic validation to avoid alert fatigue” ], “alert_logic”: { “trigger_conditions”: [ “Competitor gains top-3 position on high-volume keyword”, “Your page drops >5 positions on money keyword”, “New competitor enters top-10 for tracked term”, “Sudden visibility swing (>20%) for priority cluster” ], “priority_scoring”: “Calculate based on: search_volume * position_change * commercial_intent” }, “output_schema”: { “alert_payload”: { “alert_id”: “string”, “timestamp”: “ISO8601”, “severity”: “critical|high|medium|low”, “competitor”: “string”, “keyword”: “string”, “change_details”: { “previous_position”: “number”, “new_position”: “number”, “delta”: “number”, “search_volume”: “number” }, “impact_assessment”: “string”, “recommended_action”: “string”, “deep_link”: “string (SERP or tool URL)”, “notification_channels”: [“slack”, “email”] } }, “notification_templates”: { “slack”: “🚨 {severity.toUpperCase()} Alert: {competitor} just {delta > 0 ? ‘gained’ : ‘lost’} {Math.abs(delta)} positions for ‘{keyword}’ ({search_volume.toLocaleString()} vol). {recommended_action} <{deep_link}|View SERP>”, “email_subject”: “[{severity.toUpperCase()}] Competitor Alert: {keyword} – {delta} position change”, “email_body”: “Competitor ‘{competitor}’ moved from #{previous_position} to #{new_position} for ‘{keyword}’. Impact: {impact_assessment}. Next step: {recommended_action}” }, “constraints”: { “format”: “JSON ONLY”, “markdown_in_output”: false, “explanatory_preamble”: false, “parse_ready_for_n8n”: true, “rate_limit_handling”: “Queue alerts if webhook limit reached”, “deduplication”: “Suppress duplicate alerts within 24h window” }, “input_variables”: { “ranking_data”: “{{ $json.competitor_rankings }}”, “baseline_data”: “{{ $json.historical_baseline }}”, “alert_thresholds”: “{{ $json.user_config }}” }, “energy_profile”: “HIGH_VELOCITY_PROACTIVE_MONITORING”, “target_user”: “SEO specialists & digital marketers managing enterprise keyword portfolios who demand instant competitive intelligence without manual monitoring”, “success_metric”: “Alert delivered <60s after detection, with 95%+ actionability score” }
Pro n8n Implementation Tip: Chain this prompt after a Schedule Trigger + HTTP Request (to your rank tracker API). Use a Switch node to route severity: critical alerts to Slack via webhook and medium/low to a daily email digest. Add a Google Sheets node to log all alerts for trend analysis. That’s how you build a 24/7 competitor watchtower—zero manual checks required.
Template 5, generate meta tags and schema markup for older pages
Old content often ranks below its real potential. This workflow takes page content or a brief, then drafts fresh meta titles, meta descriptions, and schema markup for legacy pages.
The stack usually includes an input node, OpenAI, an optional formatting step, and a CMS or spreadsheet output. If you publish to WordPress, examples like this SEO content creation workflow for WordPress show how easy it is to plug content generation into publishing systems.
JSON Prompt:
{ “agent_identity”: “Meta & Schema Revival Engine”, “mission_statement”: “Breathe new life into aging content. Maximize CTR. Automate technical SEO. Turn dormant pages into ranking assets instantly.”, “core_task”: “Analyze existing page content and current SERP trends. Generate optimized meta titles, descriptions, and valid Schema.org markup. Ensure all output is ready for bulk deployment via n8n.”, “performance_directives”: [ “⚡ BATCH READY: Process hundreds of pages without format drift”, “🎯 CTR OPTIMIZED: Write compelling titles within 60 characters”, “📝 DESC PRECISION: Meta descriptions under 160 characters, action-oriented”, “🛠 SCHEMA VALID: Generate strict JSON-LD schema (Article, Product, FAQ, etc.)”, “🚫 ZERO FLUFF: Output strictly valid JSON. No markdown. No chatter.”, “🔍 CONTEXT AWARE: Match schema type to content structure automatically” ], “output_schema”: { “optimization_data”: { “url”: “string”, “meta_title”: “string”, “meta_description”: “string”, “schema_type”: “string”, “schema_markup”: “object (JSON-LD structure)”, “confidence_score”: “number (1-10)”, “changes_made”: [“string”] } }, “constraints”: { “format”: “JSON ONLY”, “markdown_wrapping”: false, “explanatory_text”: false, “char_limits”: { “title”: 60, “description”: 160 }, “schema_standard”: “Schema.org JSON-LD”, “error_handling”: “Return null values with error flag if content is insufficient” }, “input_variables”: { “page_content”: “{{ $json.page_content }}”, “target_keywords”: “{{ $json.primary_keywords }}”, “current_meta”: “{{ $json.existing_meta }}” }, “energy_profile”: “HIGH_VELOCITY_TECHNICAL_SEO”, “target_user”: “SEO specialists & digital marketers managing large content inventories who need to refresh old pages at scale without manual editing”, “success_metric”: “100% valid schema pass rate + improved CTR potential on updated pages” }
Pro n8n Implementation Tip: Connect this prompt to a Google Sheets or CMS API node to fetch old URLs in batches. Use a Code node to validate the returned JSON-LD schema before pushing updates back to your CMS (WordPress, Webflow, etc.). Add a Delay node to respect API rate limits. That’s how you refresh 500+ pages in a weekend—without touching a single editor.
Before publishing schema, validate it. A fast AI draft is helpful, but broken markup can create its own mess.
How to import these n8n templates and launch your first automation in 5 minutes
Importing an n8n template is usually easier than people expect. Open your workflows area, choose import, then paste the JSON or upload the file. After that, map your credentials, save the workflow, and run a manual test.
Use a small sample first. One keyword cluster, one page, or one row is enough. Review the output, fix the prompt or field mapping, then turn on scheduling once the result looks right.
This is where workflow bundles shine. Instead of figuring out the architecture from scratch, you start with a path that already knows where data comes in and where it ends up.
The easiest way to import a JSON workflow into n8n
First, open Workflows in n8n.
Next, choose Import from file or paste the JSON.
Then connect your credentials for the linked apps.
Save the workflow and run it manually.
After that, check each node output before you schedule it.
Common setup mistakes, and how to fix them fast
Bad API keys cause a lot of first-run failures. Re-check the key, the model name, and your billing status.
Missing app permissions also break imports. If Sheets, Slack, or Search Console won’t connect, review app scopes first.
Empty test data creates false errors. Add a few real rows before you test.
If the JSON won’t import, the file may be incomplete or malformed. Re-copy it cleanly. If requests fail under load, add a wait step to reduce rate-limit issues.
Why these free templates fit the new high-utility Micro-SaaS model
The value isn’t the prompt. It’s the operating system around the prompt.
That’s why these free templates work so well as lead magnets, low-ticket offers, or internal agency systems. They package the full path, inputs, logic, outputs, docs, and repeat use. In other words, they help people get a real result without building the machine from scratch.
A strong landing page angle almost writes itself: stop wasting hours on manual SEO tasks and download five proven n8n AI templates.
FAQ
Are n8n AI workflows beginner-friendly?
Yes, if you start small. Pick one workflow, test with a tiny dataset, and focus on the output before you add extra branches.
Do I need to code to use these templates?
Usually not. Most templates rely on visual nodes, app credentials, and light prompt edits. A small function step may help, but many workflows run without custom code.
Which template should I start with first?
Start with keyword clustering or content briefs. They’re easy to test, and the output is easy to judge. After that, stack internal linking and reporting workflows on top.
Conclusion
Loose prompts give you ideas. n8n AI workflows give you a working path to results. These five free templates help you skip setup fatigue, launch a useful automation fast, and build from one quick win to the next. Start with the easiest workflow, test it on a small sample, then stack clustering, brief creation, and internal linking into one repeatable system. If you’re ready to move faster, download the bundle and put your first workflow to work today.
5 Best Schema Generator Tools for 2026 (Ranked for Real SEO Results)
With AI Overviews and rich snippets taking over search results, basic titles and meta descriptions aren’t enough anymore. If you want stars, FAQs, product details, and other rich results, you need structured data that matches what’s on the page.
The 5 best picks for 2026 are Schema Pro, Merkle’s Schema Markup Generator, WordLift, Rank Math Pro, and InLinks, each suited to a different setup (from quick one-off JSON-LD to full site automation). This post breaks down the best schema generator tools for speed, accuracy, and control, without turning your workflow into a coding project.
First, you’ll get a quick schema primer so the terms make sense. Then you’ll see which tool fits your stack, plus practical steps to avoid errors that stop rich results from showing up.
Schema markup in 2026, what it is, why it matters, and what’s changing
Schema markup still does the same core job in 2026: it tells search engines what your content means, not just what it says. What’s changing is the stakes. Search results are more visual, more mixed (classic links plus AI answers), and more competitive. That pushes structured data from “nice to have” into “quiet advantage”, especially when you’re comparing or choosing the best schema generator tools to keep everything accurate at scale.
What schema markup is (in plain English)
Think of schema markup like labels on your content, the same way a grocery store labels products so nobody mistakes soup for sauce. Your page can look clear to a human, yet still be fuzzy to a machine. Schema adds the missing labels.
In practice, schema is structured data (usually JSON-LD) that describes your page using the Schema.org vocabulary. You are not “adding keywords”. You are declaring entities and properties, like: this is a product, this is the price, this is the author.
Common schema types you’ve probably seen, even if you didn’t know the names:
Article: blog posts and news content (headlines, author, publish date).
Organization: brand identity (logo, social profiles, contact points).
LocalBusiness: address, hours, service area, reviews.
Review: ratings tied to a real item (not generic site-wide stars).
FAQPage: question and answer pairs.
HowTo: step-by-step instructions with tools, time, and steps.
Once you see it as labeling, it gets simpler: you’re helping Google avoid guessing.
The real benefits in 2026: richer SERP features, better understanding, fewer wrong guesses
Schema matters in 2026 because search engines try to answer faster, summarize more, and interpret intent with less room for error. Structured data gives them a cleaner map of your page.
Here’s what you actually get out of it:
Eligibility for rich results: review stars, product info, FAQ drop-downs, breadcrumbs, and more. Schema doesn’t guarantee rich snippets, but it can be the difference between qualifying and never being considered. Google is explicit about that in its structured data and rich results documentation.
Clearer meaning for AI systems: when a model tries to summarize or cite sources, it needs clean facts (product name, price, author, business info). Schema can reduce “blended” answers where your details get mixed with someone else’s.
Better matching for search intent: if your page is a product, label it like a product. If it’s a how-to, label steps like steps. That helps systems match the page to the right queries and features.
Fewer wrong guesses: without schema, search engines infer. Inference fails most on messy pages, templated pages, and pages with repeated elements.
One more thing changes the day-to-day work: schema decay. Pages change constantly, especially ecommerce and service sites. Price changes, availability flips, FAQs get edited, authors update bios. If your markup doesn’t keep up, you get mismatches, warnings, or lost eligibility.
The safest rule: schema must match what a user can see on the page. If it’s not visible or supported, don’t mark it up.
That’s why “set it and forget it” schema rarely holds up in 2026. The best results come from systems that update markup when content changes, then validate often with tools like Google’s Rich Results Test and the Schema.org validator.
JSON-LD vs. Microdata, which format should you use today?
If you’re picking a structured data format in 2026, the decision is usually simple: choose JSON-LD unless you’re stuck with a platform that forces Microdata. Both can work, and Google can read both, but the day-to-day experience is very different.
Think of JSON-LD like a clean shipping label you attach to the outside of a box. Microdata is like writing the shipping details across the cardboard flaps, tape, and seams. When the box changes shape, the message breaks.
Why JSON-LD wins for most sites (especially with AI and frequent updates)
JSON-LD keeps schema in one place, usually a single <script type="application/ld+json"> block in the head or body. That separation is the whole point. Your HTML can change without dragging your structured data down with it.
This matters more now because sites update constantly. Prices change, availability flips, authors rotate, FAQs get rewritten, and AI tools generate new sections fast. With JSON-LD, you can update schema without touching templates, CSS hooks, or fragile DOM structure. As a result, your markup is less likely to decay when the layout changes.
JSON-LD also makes QA less painful. Since it’s one block of data, you can:
Validate faster: Copy and paste one snippet into a validator, fix, and redeploy.
Diff changes cleanly: In Git, schema edits show up as clear JSON changes, not scattered HTML attribute edits.
Automate safely: Many of the best schema generator tools output JSON-LD by default, because it’s easier to generate reliably.
For larger sites, the scaling story is even better. You can generate JSON-LD from a CMS, a product feed, or server-side rendering, then apply it consistently across thousands of URLs. With Microdata, every template variation can become a new failure point.
Practical rule: if your schema lives in a script tag, redesigns usually won’t break it. If it’s mixed into HTML attributes, redesigns often will.
When Microdata still makes sense (rare cases)
Microdata can still be a reasonable choice when you have hard platform limits. Some older CMS themes, legacy ecommerce systems, or locked-down page builders only allow small inline changes inside HTML, but block script tags. In those situations, Microdata may be the only way to add structured data without a full rebuild.
It can also fit strict templating setups where you already control the exact markup, and it rarely changes. For example, a small site with a stable set of templates and minimal A/B testing might keep Microdata working for a long time, if nobody touches the layout.
Still, the trade-off is real. Microdata is easier to mess up because it’s woven into the HTML. A simple refactor (wrapping an element, moving a price, changing a component) can break the connection between itemprop fields and the entity they describe.
Before you choose Microdata, be honest about the maintenance cost:
More surface area for errors: dozens of attributes across many elements.
Harder reviews: code reviewers must scan HTML structure and attributes together.
More fragile over time: template changes can silently drop required properties.
If you inherit Microdata, it often makes sense to keep it temporarily, then migrate to JSON-LD during the next template refresh. That’s also when switching to one of the best schema generator tools can pay off, because it reduces the manual work that Microdata tends to create.
The 5 best schema generator tools for 2026 (pros, cons, pricing, best fit)
The “best” schema tool depends on how you work. If you publish at scale, you want templates, rules, and automation that keep markup aligned with page content. If you only need schema on a few pages, a fast JSON-LD generator might be enough.
To make this easy to scan, here’s a quick snapshot, then we’ll break down each pick.
Tool
Pricing style
Best fit
What it’s best at
Schema Pro
Paid plugin (annual, plus lifetime option)
WordPress agencies, large WP sites
Rules, mapping, and hands-off deployment
Merkle Schema Markup Generator
Free
One-off pages, testing
Quick JSON-LD you paste anywhere
WordLift
Paid platform (subscription)
Content-heavy brands
Entity linking, semantic SEO, knowledge graph approach
Rank Math Pro
Paid plugin (tiered annual plans)
WordPress site owners
SEO + schema in one place, strong templates
InLinks
Paid SaaS (monthly plans)
Publishers, teams
Entities, internal linking, automation across many URLs
Schema Pro: best for hands-off schema on WordPress sites
Schema Pro is built for one goal: make schema largely automatic on WordPress, without you hand-writing JSON-LD for every page. The real power is in display rules and mapping. You can assign schema types to post types (posts, pages, products), then map properties to what you already store in WordPress (title, excerpt, author, featured image) or to custom fields (like ACF).
That’s a big deal on busy sites. Instead of editing schema per URL, you set rules once and let the plugin scale it across hundreds or thousands of pages. Agencies like it because each client can have different templates, yet the workflow stays consistent.
Pros
Automation at scale: Map once, apply site-wide.
Common rich result types supported out of the box (Article, FAQ, Product, Review, LocalBusiness, and more).
Fast deployment: Great when you need coverage quickly on a large WordPress install.
Cons
WordPress-only.
Custom setups take work: If your schema rules depend on complex conditions or messy custom fields, expect setup time.
Pricing (typical paid plugin model)
Annual licensing, plus a lifetime option. See the current tiers on the Schema Pro pricing page.
Best fit
WordPress agencies and in-house teams managing large WP sites, especially if you rely on custom fields and repeatable content patterns.
Merkle Schema Markup Generator: best free option for quick JSON-LD you can paste anywhere
Sometimes you don’t need automation. You need a clean JSON-LD block you can paste into a page builder, a Shopify custom HTML section, or a static landing page. That’s where Merkle-style generators shine.
The workflow is simple: pick a schema type, fill in fields, copy JSON-LD, and publish. It’s perfect for one-off pages and fast drafts, because there’s no install, no plugin conflicts, and no site-wide settings to untangle.
The trade-off is maintenance. If the page changes, the schema won’t update itself. You have to remember to revisit it, or schema drift creeps in quietly.
Pros
Free and fast: Great for quick wins.
No install: Works with any CMS because it outputs paste-ready JSON-LD.
Low friction for testing: Ideal for validating ideas before you systemize them.
Cons
Manual updates: Every content edit can create schema mismatches.
Easy to miss required properties: Especially on Product, Review, and FAQ-like markup.
A single service landing page, a webinar registration page, a small local business site, or testing FAQ/HowTo markup before rolling it out broadly.
If your schema lives in a spreadsheet or a sticky note, it will eventually get out of sync. Free generators are best when the page won’t change often.
WordLift: best for AI-powered entity linking and semantic SEO at scale
WordLift is less of a “fill in the blanks” schema generator and more of a semantic layer for your content. Instead of only tagging pages as Article or FAQ, it focuses on entities (people, products, places, concepts) and relationships between them. That matters more in 2026 because search is increasingly about understanding topics, not just matching keywords.
On content-heavy sites, entity work can act like a map of your expertise. When your site repeatedly references the same entities, and those entities connect cleanly across articles, you end up with stronger topical consistency. Structured data becomes a byproduct of a better content model, not a separate chore.
Pros
Semantic focus: Helps you build entity clarity across a site, not just per page.
Automation for structured content: Useful when you publish a lot and need consistency.
Strong for complex topics: Especially when categories overlap and internal connections matter.
Cons
Learning curve: Teams need a shared approach to entities and editorial structure.
Cost: It’s a bigger investment than a simple generator.
Overkill for small sites: If you publish occasionally, you won’t use its depth.
Pricing
Typically subscription-based. For plan and feature context, you can cross-check third-party summaries like WordLift listings and user feedback.
Best fit
Content publishers, SaaS companies, and brands with deep libraries (or ambitious publishing plans) where entity consistency is worth the effort.
Rank Math Pro: best all-in-one SEO plugin with strong schema controls
Rank Math Pro is the “one dashboard” option. You manage SEO settings and schema in the same place, which reduces context switching and keeps workflows simple for WordPress teams. For many sites, that’s the whole point: you don’t want a separate schema system unless you truly need it.
Schema-wise, Rank Math is strong because it offers schema templates you can apply per post type or per page, including common rich result formats like FAQ, HowTo, Article, and Product. You can also customize fields, set defaults, and roll schema out quickly across content.
Pros
Convenient UI: Friendly schema controls without touching code.
Flexible templates: Good coverage for typical content and marketing pages.
Fast deployment: Easy to standardize schema while you handle other SEO tasks.
Cons
WordPress-only.
Can add complexity: If you already run another SEO plugin, switching or doubling up can create conflicts and confusion.
WordPress site owners who want strong schema controls, but also want keyword tracking, on-page checks, and other SEO features in one plugin.
InLinks: best for combining internal linking, entity optimization, and automated structured data
InLinks is best viewed as a content optimization system that happens to produce schema, not a simple schema generator. Its core strength is entity-driven organization: it helps you understand what your pages are about, how they connect, and where internal links and topic coverage are weak.
That broader approach can support schema in a more durable way. When your content is organized around entities and topic clusters, your structured data tends to stay consistent too. For large blogs and publishers, this becomes a workflow advantage because you’re improving multiple ranking inputs at once.
Pros
Entity-driven suggestions: Helps keep topic coverage clean and consistent.
Scales across many pages: Built for large sites that need repeatable processes.
Publishers, large blogs, and content teams who want internal linking, entity optimization, and structured data working together across hundreds of URLs.
Hands-on: how to create schema with Google’s Structured Data Markup Helper (and when you should not)
Google’s Structured Data Markup Helper can still help you understand what structured data is trying to describe. It’s a training-wheels workflow for mapping page elements to fields. That said, it often nudges you toward older, fragile implementations, so treat it as a learning and prototyping tool, not your long-term schema system.
When you’re aiming for real SEO results in 2026, most teams get better outcomes with the best schema generator tools that output clean JSON-LD and fit your stack. Still, if you want a fast, hands-on way to see how “tagging” works, here’s a practical walkthrough.
Step-by-step walkthrough you can follow in 10 minutes
Use this flow when you’re marking up a single page and you want a quick draft to refine.
Open the Structured Data Markup Helper. If you can’t find it easily, that’s a hint it’s no longer a primary Google workflow in 2026. Keep going only if you’re prototyping.
Enter a page URL (or paste HTML). Use a page that’s publicly accessible and stable, like a published blog post or product page. Avoid pages behind logins or heavy personalization.
Pick the closest data type. Choose something like Article, Product, LocalBusiness, Event, or Recipe. If you’re between two, pick the one that matches the page’s main purpose.
Tag elements in the preview. Highlight visible content (title, author, price, FAQs) and assign the matching fields. Move slowly here. One wrong tag can ripple into a broken entity.
Keep the markup aligned with what users can see. Don’t tag hidden tabs, collapsed content that isn’t accessible, or “marketing claims” that aren’t on the page. If a user can’t verify it, don’t mark it up.
Generate the code. Export the output. Then treat it as a draft, not a final artifact. You usually need to clean it up and convert to JSON-LD if it outputs Microdata.
Place the schema in the right spot (JSON-LD best practice). If you end up with JSON-LD, add it in a single <script type="application/ld+json"> block. Most sites place it in the <head>, although Google can read it in the body too. Pick one convention and stick to it.
Validate before you publish (and after). Run the live URL or code through the Rich Results Test. Fix errors first, then re-test. After publishing, watch Search Console rich result reports for warnings.
If you ship schema you didn’t validate, you’re guessing. Validators catch missing required fields and mismatched types before Google does.
When you should not use the Markup Helper: Skip it if you need schema at scale, if your pages change often (prices, availability, FAQs), or if you want a clean JSON-LD workflow. In those cases, a dedicated generator, CMS automation, or an entity-based platform is more reliable.
Manual tagging vs. tools, how to pick the right approach for your site
The “right” approach is the one you can maintain. Schema that rots is worse than no schema, because it creates mismatches and lost eligibility.
Here’s a simple decision guide that matches how most teams actually work:
Use WordPress plugins when you’re on WP and want ongoing accuracy. Plugins (like the ones covered in this post) can map schema to your post types and custom fields. That reduces human error, because updates happen when content updates.
Use generators for small sites and one-off landing pages. If you have a handful of pages, a generator that outputs JSON-LD is usually enough. The trade-off is upkeep. Someone must revisit the markup when the page changes.
Use entity platforms when you publish at scale. If you manage hundreds or thousands of URLs, manual tagging becomes a treadmill. Entity-focused platforms can keep topics, internal links, and structured data consistent across the whole site.
To make the choice concrete, compare these scenarios:
Your situation
Best approach
Why it fits
5 to 20 mostly static pages
JSON-LD generator
Fast setup, low overhead
WordPress blog or store that changes weekly
WP schema plugin
Lower maintenance, fewer mismatches
Large content site with multiple authors
Entity platform
Consistency across categories, better long-term control
Custom app (Next.js, Rails, Django)
Manual JSON-LD in templates
Precise control, integrates with your data layer
One final rule keeps you out of trouble: treat schema like code, not decoration. Version it, review it, and update it when the page changes. That’s how the best schema generator tools earn their keep, they reduce maintenance as your site grows.
Advanced schema that tends to move the needle: FAQ, Product, and Recipe
If you want structured data that people actually notice in the SERP, focus on the schema types tied to intent rich queries. FAQPage, Product, and Recipe are the big three because they map cleanly to what searchers want next: a quick answer, a confident buy decision, or a recipe they can cook tonight.
That said, schema is like putting your content into a labeled bin. If the label doesn’t match what’s inside, Google can ignore it, or worse, treat it as spam. The best schema generator tools help, but they can’t save markup that’s disconnected from the page.
FAQ schema: how to qualify for helpful Q and A displays without risking spam
FAQ schema looks simple, which is why it’s often abused. The safest approach is to treat it like documentation: clear questions, direct answers, and zero hype. Also, remember that FAQ rich results are not guaranteed. Results vary by query, site, and what Google chooses to show.
Before you ship, sanity check your page using this practical checklist:
Real Q&A is on the page: Every question and answer in your JSON-LD must be visible to users (not hidden in tabs that never load, popups, or accordion content that isn’t accessible).
Answers stay short and factual: Aim for quick, complete answers that a human can skim. If it sounds like ad copy, rewrite it.
Avoid marketing fluff: Don’t stuff CTAs, pricing pitches, or “best in class” claims into answers. Keep it neutral.
One question, one answer: FAQPage is for a single authoritative answer, not a community thread. If you have discussions, that’s a different markup type.
Update schema when content changes: If you edit the FAQ section, update the FAQ markup the same day. Otherwise you create mismatches that can kill eligibility.
A good rule: if your FAQ section wouldn’t help a customer support rep, it probably won’t help your search snippet either.
Product and Recipe schema: the fields that most often get missed
Product and Recipe schema are where small omissions cost you. A generator might output “valid” JSON-LD, but still miss the properties that help rich results (or merchant features) trigger. So, think in terms of “what would a shopper or cook want to know instantly?”
Product schema fields that get skipped most often:
name and image: Don’t use placeholders or tiny images. Match what’s on the product page.
offers.price + offers.priceCurrency: Pricing should match the page and update when it changes.
offers.availability: Keep stock status accurate, especially if inventory flips often.
brand: Add it when it’s known and visible.
sku or gtin (GTIN-12, GTIN-13, etc.): Include identifiers if you have them. They help disambiguate similar products.
Reviews and ratings only if shown: Mark up aggregateRating and review only when users can see the same rating content on the page.
If you want a reference list of common fields and pitfalls, this Product schema markup guide is a solid checklist.
Recipe schema fields that get missed most often:
name and image: Recipe rich results are visual, images matter.
prepTime and cookTime: Include both when you display them. If you only have total time, still be consistent.
recipeIngredient: Use a real ingredient list, not a paragraph.
recipeInstructions: Steps should be structured as steps, not one long blob.
nutrition (only if present): If you show calories or macros, mark them up. If you don’t, skip it.
Finally, prioritize implementation in this order: high-traffic money pages first, then category-level templates, then long-tail content. That’s where the best schema generator tools pay off, because they help you roll out correct markup across the pages that already have demand.
Fix schema errors fast: common Search Console issues and a simple troubleshooting flow
When Google Search Console flags structured data errors, it’s rarely mysterious. Most failures come from a handful of repeat patterns: missing fields, mismatched on-page content, or formatting that looks fine to humans but breaks parsers.
The upside is that you can fix most issues in minutes if you follow the same flow every time. That’s also where the best schema generator tools earn their keep: they reduce the “death by tiny mistakes” that happens when schema gets edited in five places by five people.
The most common problems (and what they usually mean)
Search Console error labels sound technical, but they point to simple realities: Google could not find a required value, could not parse a value, or thinks your markup doesn’t match what users see.
Here are the issues that show up the most, plus what they typically mean in practice:
Missing required field: You picked a rich result type that has mandatory properties, but your markup omits one. For example, Product missing offers.price, or Article missing headline. This often happens when templates pull from fields that are empty on some pages.
Invalid value type: The property exists, but the value is the wrong kind. A common example is using a word where a number is required (rating set to "five" instead of 5), or providing a plain string where Google expects an object (like author needing a Person object).
Image too small (or invalid image): Your page uses tiny thumbnails, SVGs, blocked images, or images that Googlebot can’t fetch. This is common on ecommerce when the schema points to a CDN URL that requires cookies or blocks bots. It can also happen when schema generators map to a “featured image” that is not the same as the main visible product image.
Price format wrong: Prices need consistent formatting. You’ll see this when a template injects currency symbols into numeric fields ("$29.00" instead of 29.00), or when localization changes decimals and separators. Another classic failure is showing a price range on-page but marking one fixed price in schema.
aggregateRating without visible reviews: This is a big one. If you add rating markup but the page doesn’t show the actual rating and review count to users, Google can treat it as misleading and ignore it. The clean fix is simple: either show real review content on-page, or remove rating markup.
FAQ marked up without real questions on the page: FAQ schema must reflect visible Q&A content. People often mark up “objections” or sales copy as FAQs, or load questions behind tabs that never render for bots. If a user can’t see the questions and answers, don’t mark them up.
If you remember one rule, make it this: schema is a mirror, not a wish list. It should reflect what’s on the page, not what you want Google to show.
A repeatable checklist to get back to “valid” and avoid repeat mistakes
Treat structured data like a build step. You don’t need a huge process, but you do need the same order of operations each time. Otherwise you’ll “fix” the symptom and ship a new issue on the next deploy.
Run this checklist in order:
Validate the exact code Google sees Start with the live URL, not a staging snippet. In Search Console, open the affected URL, then test the page with a validator. Fix parsing errors first, because one broken bracket can trigger a pile of fake “missing field” errors.
Confirm the page content supports every claim Open the page like a user would. Can you visually confirm the price, availability, rating, and FAQs? If not, you’re sitting on a mismatch. Align markup to what’s visible, or update the page content so it truly matches.
Keep one main schema per intent Pick the “primary” entity that matches the page goal. A product page should be mainly Product. A how-to article should be mainly HowTo or Article, depending on intent. You can include supporting nodes (BreadcrumbList, Organization, WebSite), but avoid stacking multiple competing primary types that describe the page as different things.
Avoid marking up hidden or gated content If content is in a tab, accordion, modal, or loaded after user interaction, verify it still renders in the initial HTML. When in doubt, keep markup to content that is visible by default. This is where a lot of FAQ and review markup gets sites in trouble.
Keep templates consistent across page variants Most “random” errors are actually template drift. One category template outputs offers, another doesn’t. One author bio includes sameAs, another is blank. Tighten mappings so optional fields fail gracefully, and required fields never rely on a sometimes-empty custom field.
Revalidate after theme or plugin changes Theme updates, SEO plugin toggles, ecommerce app updates, and even image optimization plugins can break schema outputs. After any change, spot-check a few representative URLs (top product, top blog post, one category page) and re-run validation.
To prevent repeat fires, set one simple team rule: schema changes require a quick spot test on 3 URL types (a money page, a content page, and a template outlier). That tiny habit catches most issues before Search Console does. For a broader debugging workflow, this guide is a solid companion: how to fix structured data errors in Search Console.
AI is changing schema automation, what to expect from the best tools in 2026
In 2026, the best schema generator tools are starting to feel less like form-fillers and more like autopilots. They can read your page (or feed), infer the right schema type, and output JSON-LD that looks clean on first pass. That speed is real, and it saves hours, especially when you are rolling out markup across hundreds of URLs.
Still, AI schema automation has a catch: it can sound confident while being wrong. So the winning workflow is simple, use AI for 80% of the work, then verify the 20% that can hurt you.
What AI can do well (speed, suggestions, consistency) and what it still gets wrong
AI earns its keep when the job is repetitive and rule-based. For example, it can map the same set of fields across every product page, keep formatting consistent, and suggest useful properties you might forget.
Here’s what AI-driven schema tools tend to do well:
Speed at scale: Generate workable JSON-LD from a URL, HTML, or feed in seconds, then repeat it across page templates.
Smart suggestions: Recommend properties like brand, sku, gtin, offers.availability, or sameAs when your content supports them.
Consistency: Keep date formats, price formats, and required fields uniform across thousands of pages, which is where manual work usually breaks.
However, AI still makes the same three mistakes, and they are the ones that cost you rich results.
First, hallucinated properties show up more than people admit. A tool might invent a rating value, guess an author, or add aggregateRating because “most product pages have it.” That is how you end up marking up claims you cannot prove on-page. Many AI tools even warn about this risk in their own disclaimers, which is worth taking seriously (see SchemaSense’s note on AI output limits).
Second, AI can produce mismatched values. It may scrape the wrong price (sale vs regular), pick the wrong image (thumbnail vs main), or confuse variants (size, color). This hits ecommerce hardest because prices and availability change often.
Third, it sometimes marks up content that isn’t visible. Hidden reviews, collapsed FAQ answers that do not render server-side, or data loaded only after interaction can turn into a mismatch. That mismatch is easy for Google to ignore, and hard for you to debug later.
Treat AI schema like a junior developer’s pull request, it can be great, but you still review the diff.
A quick spot-check routine keeps you safe, especially for Product and Review markup:
Open the page and confirm visibility: If users cannot see the rating, price, or FAQ answer, don’t mark it up.
Compare key fields: Check name, image, price, availability, reviewCount, and ratingValue against what is on the page right now.
Validate before shipping: Run the final output through the Rich Results Test and a schema validator, then re-check after template updates.
Do that, and AI becomes a multiplier instead of a liability.
FAQ
Schema can feel simple until you try to scale it across templates, products, and constant content updates. This FAQ covers the questions that come up most when people compare the best schema generator tools and try to ship markup that stays valid over time.
What is a schema generator tool, and what does it actually produce?
A schema generator is a tool that turns plain info (like a product price, an author name, or a list of FAQs) into structured data. In most cases, it outputs JSON-LD, which you add to the page inside a <script type="application/ld+json"> tag.
Think of it like a barcode maker for your content. A scanner cannot guess the price from a shelf photo. In the same way, search engines cannot always “guess” what your page means from layout alone. The generator gives them a clean, standard format to read.
Most schema generators fall into three buckets:
Form-based generators: You fill in fields, then copy and paste JSON-LD (great for one-off pages).
CMS plugins: You map schema to your CMS data (best for WordPress sites with lots of content).
Entity platforms: They connect topics, entities, internal links, and markup across many URLs (best for publishers and big content teams).
If you want to sanity-check what you generated, Google’s structured data guidance is still the best baseline for what search engines expect.
Do schema generator tools guarantee rich results or AI Overview visibility?
No. Schema does not guarantee rich results, and it does not force AI systems to cite you. What it does is make you eligible for certain enhancements, and it reduces confusion about what your page represents.
Here’s the practical reality: rich results depend on query intent, competition, site quality signals, and whether Google wants that feature in the SERP at all. Even perfect markup can show no visible change for some queries.
Still, schema often pays off in three quieter ways:
Cleaner interpretation: Your page is less likely to be misread (product vs article, brand vs author, FAQ vs support doc).
More consistent extraction: Systems can pull exact fields like price, availability, author, and datePublished with less guesswork.
Fewer eligibility issues: Valid markup keeps you from self-sabotaging when templates change.
Treat schema like seatbelts. They don’t make you win the race, but they prevent avoidable damage when things go wrong.
If you’re chasing visible SERP changes, focus first on schema types that match the page’s main job (Product for product pages, Article for posts, LocalBusiness for local pages). Then validate and keep it updated.
Where do I add JSON-LD on WordPress, Shopify, or a custom site?
The clean answer is: add JSON-LD once per page, and make sure it matches what users can see.
Common options that work well:
WordPress: Use a schema plugin (or your SEO plugin’s schema features). If you must add it manually, place it in the header via a code snippet plugin, your theme, or a custom hook.
Shopify: Prefer theme-level integration or an app that injects schema from product data. For a one-off landing page, you can sometimes add JSON-LD in a custom section, but keep it maintainable.
Custom sites (Next.js, Rails, Django, etc.): Generate JSON-LD server-side from the same data source that renders the page. That keeps content and schema aligned.
Two placement rules keep you safe:
Avoid duplicates: If two tools output Product schema, you can end up with conflicting entities. That can cause warnings, or just muddy results.
Avoid “floating” schema: Don’t inject schema through random scripts that are hard to trace later. When the page updates, your schema drifts.
When in doubt, pick one owner for schema output. One system, one source of truth.
What are the most common mistakes that cause schema warnings or rich result loss?
Most schema problems are not “advanced.” They are small mismatches that pile up.
The mistakes that show up again and again:
Markup does not match the visible page: For example, schema says “In stock,” but the page says “Sold out.”
You mark up reviews that aren’t on the page: Adding aggregateRating without visible ratings is a classic way to lose trust.
Wrong data types: Price values formatted like "$29.00" instead of 29.00, or dates in messy formats.
Hidden FAQ content: Questions and answers that only load after a click, or that do not render for bots.
Template gaps: Your template outputs required fields on most pages, but some pages have empty data (missing images, missing authors, missing offers).
A fast habit that prevents most issues is to validate the live URL after you publish changes. Then re-check a few representative pages after theme, plugin, or template updates.
A few years ago, many sites used FAQ markup to grab more SERP space. Today, FAQ rich results can be limited and inconsistent depending on the query and site type. That said, FAQ schema still has value because it clarifies Q-and-A content for machines, especially when your page truly contains a support-style FAQ section.
FAQ schema is worth it when:
The FAQ is real and helps users decide or troubleshoot.
The answers are direct, not sales copy.
You can keep the markup synced with edits.
FAQ schema is not worth it when:
You’re trying to “manufacture” questions just to rank.
Your FAQ is a thin wrapper around keywords.
Your content changes weekly and nobody owns upkeep.
If you want a deeper set of do’s and don’ts, see FAQ schema best practices for 2026. Use it as a policy doc for your team, not as a copy-paste playbook.
Which schema generator tool should I choose for my site?
Start with the workflow you can maintain. The “best” tool is the one that keeps schema accurate when your site changes.
A simple decision shortcut:
One-off pages or small sites: Use a free generator, then paste JSON-LD. It’s quick, but you must remember to update it.
WordPress sites that publish often: Use a plugin-based tool so schema updates when content updates. This is where the best schema generator tools usually win on real results, because they prevent drift.
Large content libraries: Choose a system that ties schema to entities and templates across many URLs, not page-by-page edits.
Before you commit, verify these two things in any tool:
Control: Can you edit fields and remove risky properties (like ratings) when they are not supported?
Validation: Can you catch errors before Search Console does, ideally with built-in checks?
If the tool can’t help you stay consistent, it will cost you more time than it saves.
Conclusion
Schema is essential in 2026 because it helps search engines understand what your page is, and it keeps you eligible for rich results that earn clicks. JSON-LD stays the safe default because it is easier to maintain, easier to validate, and less likely to break when templates change. The best schema generator tools (Schema Pro, Merkle, WordLift, Rank Math Pro, and InLinks) help you move faster, but validation is what stops that speed from turning into warnings, mismatches, and wasted effort.
Start simple: pick one page type (Product, FAQ, or Article), generate markup, test it in Google’s Rich Results Test, then scale the same pattern across templates. If you want a low-effort next step, keep a one-page technical SEO audit checklist next to your deploy process, then spot-check schema after every theme, plugin, or feed change.
Kore.ai IT Automation for Service Desks: 25 Ready-to-Deploy Prompt Workflows from the Marketplace
Service desks don’t usually fall behind because teams don’t care. They fall behind because the work never stops. The same password resets, access requests, and “VPN isn’t working” tickets keep coming, while MTTR creeps up and hiring stays tight. Meanwhile, manual steps create risk, because a tired tech at 2 a.m. can click the wrong thing.
Kore.ai IT automation tackles that pressure with “ready-to-deploy prompt workflows” you can pull from a Marketplace and put into production quickly. In plain terms, these are pre-made automation recipes: prompts, decision steps, and tool connections that guide a request from intake to completion, with logging and guardrails.
This post maps 25 practical workflows by category, what each one does, and how to roll them out from the Kore.ai Marketplace without turning automation into a new source of incidents.
Why Kore.ai IT automation beats building every service desk workflow from scratch
Building custom automations feels safe, because you control every line. In practice, it’s slow. A “simple” workflow often turns into weeks of meetings, edge cases, and rework once it hits real tickets. By the time it ships, the queue has already changed.
Pre-built Marketplace workflows flip the timeline. Instead of designing everything, you start from a working pattern, then tailor it. That matters for a Senior IT Ops Manager because you’re measured on outcomes, like fewer escalations and faster restores, not on how elegant the flowchart looked.
Here’s the business case that usually lands:
Faster time-to-value: start with high-volume L1 tasks and expand.
Fewer L1 and L2 touches: the workflow gathers details, runs checks, and only escalates when needed.
Consistent execution: the same steps happen every time, even on weekends.
Better auditability: actions can be logged back to tickets and change records.
The hidden costs of manual work add up quickly: context switching between chat and tickets, copy-pasting error logs, missed fields that trigger re-triage, escalations that bounce between teams, and after-hours pages caused by “quick fixes” that weren’t tracked.
If you want a vendor-level view of what Kore.ai positions as its workflow approach, see its overview of intelligent process automation.
What “ready-to-deploy” really means in the Kore.ai Marketplace
“Ready-to-deploy” shouldn’t mean “works in the demo.” In this context, it typically means the workflow already includes the pieces that take the longest to design:
Prompts and conversation paths that ask for the right details (device, error, urgency, impact).
Decision steps to route work based on policy (role, app, environment, change window).
Connector mappings to common enterprise systems (ITSM, IAM, cloud, security tools).
Basic guardrails, so risky actions don’t run without checks.
Kore.ai also emphasizes multi-agent orchestration for IT work, where different agents can handle different task types, and route between them without the user feeling the handoff. In March 2026, Kore.ai also highlights pre-built templates at scale (it publicly references dozens of templates and broad enterprise integrations). For background, Kore.ai describes its library of pre-built process templates and how they speed up common automation patterns.
You still customize, but you customize what matters: language, routing rules, approvals, and ticket fields, without turning every request into a mini software project.
Governance and safety basics, so automation does not create new risk
Automation that can change systems must behave like a careful engineer, not an eager intern. Start with a few basics that keep security and audit teams calm:
Role-based access control: only allow approved groups to run workflows that change state (restart services, isolate endpoints, scale storage).
Approvals for risky actions: especially for production changes and anything disruptive.
Audit logs: capture who requested what, what the bot did, and what it changed.
Environment limits: keep “do the thing” actions restricted to dev or staging until you explicitly allow prod.
Human-in-the-loop (HITL) is the simplest safety net. The assistant prepares the action and the change summary, then a person confirms. That’s a clean way to enforce policies like least privilege, “ticket required for change,” and change-window rules.
A useful rule: let the bot gather, verify, and propose by default. Allow it to execute only when policy and permissions make it low-risk.
For more context on Kore.ai’s Marketplace positioning and how it packages enterprise-grade agents and templates, review the Kore.ai Marketplace overview.
The 25 Kore.ai Marketplace workflows that deflect tickets and speed up resolution
The workflows below are grouped the way most ops teams actually work: ITSM first, then stability, then identity, then security, then the “busywork” category that quietly drains senior engineers. Each workflow lists what it automates, likely triggers, common systems, and the outcome you can measure.
ITSM and helpdesk quick wins, 5 workflows that shrink the queue first
Password reset (self-service): Trigger chat portal, touches IAM directory, outcome is ticket deflection and fewer L1 calls.
New ticket creation with smart fields: Trigger chat or email intake, touches ServiceNow or Jira Service Management, outcome is better routing and fewer back-and-forths.
Account unlock: Trigger chat, touches AD or identity provider, outcome is faster restores and fewer escalations.
Ticket status lookup and next update: Trigger chat, reads ITSM, outcome is fewer “any update?” tickets.
Smart escalation with summarization: Trigger aging ticket or unhappy user signal, posts summary and steps tried to ITSM, outcome is faster L2 start and lower reopen rate.
Best practice: verify identity before resets, capture device and error details up front, summarize what was attempted, and write actions back to the ticket. Those four habits alone can cut re-triage.
If you want another deployment path beyond Kore.ai’s own Marketplace, Kore.ai also appears in enterprise catalogs like Microsoft AppSource for ITAssist, which can help procurement and approvals in Microsoft-heavy shops.
Cloud and infrastructure stability, 5 workflows that reduce downtime
6. VM provisioning request: Trigger chat or catalog request, touches AWS, Azure, or GCP plus CMDB, outcome is faster delivery with standard tags. 7. Automated backup verification: Trigger schedule, checks backup jobs and alerts on failures, outcome is fewer “we found out during restore” surprises. 8. Restart service with pre-checks: Trigger alert or ticket, touches Kubernetes, systemd, or cloud runbooks, outcome is shorter incident time for known failure modes. 9. Storage scaling request with approvals: Trigger ticket, touches cloud storage, outcome is fewer capacity pages and controlled growth. 10. System health checks and daily digest: Trigger schedule, pulls health metrics and posts summary to ops channel, outcome is fewer blind spots.
Safe defaults matter here. Restrict who can run scale actions, require approvals for production, and include rollback steps when possible. For restarts, add guardrails like “only restart once per X minutes” and “do not restart during maintenance freeze unless approved.”
Identity and access at scale, 5 workflows that cut onboarding and access delays
Employee onboarding checklist: Trigger HR event or ticket, touches Okta or Microsoft Entra ID, outcome is day-one readiness and fewer manual tasks.
Offboarding and access removal: Trigger HR termination event, disables accounts and removes group access, outcome is lower security exposure and stronger audits.
App access request with approvals: Trigger chat, routes to manager and app owner, outcome is faster access with policy-compliant approvals.
MFA reset with identity proofing: Trigger chat, touches IAM, outcome is quick restores without social-engineering gaps.
Role change request (least-privilege templates): Trigger ticket, maps to role bundles, outcome is fewer one-off entitlements and cleaner access reviews.
Keep these workflows zero-trust minded: time-bound access where possible, manager approval, audit trails, and role templates instead of ad hoc group adds. When exceptions happen, force an explicit reason field so you can report on it later.
For a sense of what Kore.ai says it’s releasing and improving around enterprise productivity and agents, its update posts can be helpful context, such as Kore.ai AI for Work feature updates.
Security operations that move fast, 5 workflows for incident response support
Phishing alert triage intake: Trigger user report in chat, collects headers and indicators, outcome is faster triage and fewer incomplete reports.
Endpoint isolation request (HITL): Trigger SOC chat or incident ticket, proposes isolation, requires analyst approval, outcome is quicker containment with control.
Vulnerability scan kickoff: Trigger schedule or change ticket, starts scan and posts results, outcome is tighter patch loops.
Log retrieval for an incident ticket: Trigger incident workflow, pulls relevant logs and attaches them, outcome is less swivel-chair investigation.
Mass incident notifications and status updates: Trigger major incident declaration, sends updates and keeps a timeline, outcome is fewer inbound pings and clearer comms.
These flows should bridge to SIEM and SOAR tools at a high level, but keep destructive actions gated. A good design principle: the assistant can enrich and summarize freely, but it executes containment only with approvals.
Network, asset, and software busywork, 5 workflows that free up engineer time
Software deployment request intake and approvals: Trigger chat, routes to app owner, then triggers deployment tool, outcome is fewer manual installs.
VPN troubleshooting guided flow: Trigger chat, runs checks (client version, auth, network), outcome is fewer escalations to networking.
License audit reporting: Trigger schedule, reconciles users and licenses, outcome is fewer true-up surprises.
Asset tracking updates: Trigger user self-report or warehouse scan event, updates asset system, outcome is cleaner inventory.
Network diagnostics runbook: Trigger ticket or chat, runs ping, DNS checks, traceroute collection, outcome is faster isolation of “network vs app” issues.
Think of this bucket as a conversational command center: one place to request actions and get answers, with every step logged. Also, Marketplace prompts should be treated as a starting point, then tailored to your naming, tools, and policies without weakening approvals and access controls.
Deploy a Kore.ai Marketplace workflow in minutes, a practical rollout plan that sticks
Fast deployment only matters if it stays live. The rollout that usually works is boring on purpose: pick one high-volume use case, ship it with guardrails, measure, then expand. That approach also helps with change management because agents and users can build trust one workflow at a time.
Treat your first workflow like a product release. Assign an owner, set a success metric, and test in a safe environment. Then make the self-service entry point obvious, such as Teams, Slack, a portal widget, or the ITSM catalog.
If your org prefers buying through cloud marketplaces, Kore.ai also lists offerings in places like the AWS Marketplace AI for Service listing, which can simplify procurement in some enterprises.
From selection to go-live, a clear checklist for first deployment
Pick one high-volume use case (password reset, unlock, ticket intake).
Define one success metric (deflection rate or handle time).
Confirm data sources (knowledge articles, policy docs, ticket fields).
Connect your ITSM (ServiceNow, Jira Service Management, or Zendesk).
Configure auth securely (scoped tokens, least privilege, rotation plan).
Map fields and outputs (summary, category, CI, impact, resolution notes).
Set approval rules for risky steps (prod changes, access grants, isolation).
Run test tickets in a sandbox and capture failure patterns.
Pilot with one team for one to two weeks, then expand.
Train agents and announce self-service, and keep a clear fallback path to a human.
How to measure ROI in the first 30 days without fancy math
Skip complex models. Use simple, defensible metrics you can explain in a staff meeting:
Ticket deflection rate: how many requests ended without an agent touching the ticket.
Average handle time (AHT): how long agents spend per ticket when they do engage.
Time-to-first-response: especially important for chat-based intake.
Escalation rate: shows whether intake and summaries improved.
After-hours pages: a practical signal that stability workflows are working.
Set a weekly review cadence: top failure reasons, prompt tweaks, routing tweaks, and knowledge gaps to fix. Include an audit and compliance spot-check in that review so your controls don’t drift over time.
FAQ (Frequently Asked Questions From Readers)
Do I need to automate everything to see results?
No. Start with one workflow that represents a big slice of volume, like password resets or ticket intake. Then expand once metrics prove it.
Will automation frustrate users if the bot gets it wrong?
It can, so design for graceful exits. Make it easy to route to a human with a clean summary, not a blank handoff.
How do approvals work for risky actions?
Use HITL for disruptive actions, like endpoint isolation or production scaling. The assistant proposes the action and a person confirms.
Where does knowledge come from for troubleshooting flows?
Good workflows pull from your internal docs and ticket history patterns. Keep the source set small at first, then broaden after you see consistent answers.
What’s the fastest place to begin in Kore.ai IT automation?
Begin with an ITSM workflow that collects better details and logs actions back to tickets. That improves outcomes even before you automate “doer” actions.
Conclusion
If your service desk feels like a treadmill that keeps speeding up, you don’t need a year-long rebuild. Pick one or two ITSM quick wins, deploy them with approvals and audit logs, and measure impact for 30 days. After that, expand into IAM and cloud stability, where small delays and manual steps often create the biggest risk.
The practical promise of Kore.ai IT automation is simple: faster time-to-value using ready-to-deploy Marketplace workflows, less manual work, and more consistent support. Choose a workflow tied to a real pain point, run a focused proof-of-concept, and let the results decide what you automate next.
AI Prompts for Finance Reconciliation: 15 Epic Prompts for Automated Agents That Match, Flag, and Summarize Fast
Month-end close has a special kind of cruelty. It’s 10:47 p.m., your eyes burn, and the last “small” mismatch turns into a two-hour hunt across bank exports, card feeds, and the general ledger.
AI prompts for finance reconciliation can flip that script. With the right instructions, an AI reconciliation agent can match transactions, flag exceptions, and draft clean notes in minutes, not days.
In plain words, a “reconciliation agent” is an AI helper that takes your files, matches records across sources, and explains what didn’t match and why. You still approve the final entries, because finance controls matter, but the agent does the heavy sorting and first-pass analysis.
How automated reconciliation agents work, and what makes a prompt “good” in finance
A solid reconciliation agent follows a predictable path. First, it ingests your sources (bank CSVs, card statements, payment processor payouts, and GL exports). Next, it normalizes fields (dates, amounts, vendor names). Then it matches records using rules plus “fuzzy” logic, scores confidence, routes exceptions, and produces notes you can keep for audit support.
That’s the promise behind many modern reconciliation tools and workflows, especially as teams move toward continuous checks instead of waiting for month-end. If you want a broader sense of how vendors describe audit-ready close workflows, see AI-powered reconciliations for faster closes.
A “good” finance prompt is strict. It doesn’t sound creative, because you’re not writing poetry. You’re writing operating instructions.
Here’s a quick checklist you can reuse:
Role and goal: “You are a reconciliation analyst. Your job is to match X to Y.”
Accepted formats: CSV columns, date formats, currency codes.
Matching rules: date window, amount tolerance, vendor normalization rules.
Required outputs: match table, exceptions table, summary stats.
Audit trail notes: cite source row IDs, explain why each match happened.
Two guardrails keep you out of trouble:
Never invent transactions, never “fix” missing data, and always cite the exact source row IDs you used. If a field is missing, ask a question before matching.
The minimum inputs your agent needs to reconcile cleanly
Think of inputs like puzzle pieces. If half the pieces are missing, the agent will guess, and guessing is the enemy of clean books.
At minimum, include these fields for bank or card data:
Transaction date (and posted date if available)
Amount and currency
Description or memo
Vendor or counterparty name
Reference ID (bank ref, trace, authorization, check number)
For GL data, include:
Posting date
Amount and currency
Vendor or customer
Account name and account number
Journal entry ID (or transaction ID)
Posting period
A few optional fields can boost match rates fast: invoice number, PO number, last-4 card digits, store location, exchange rate, settlement batch ID, and payout ID.
Also, watch out for timing. A bank “transaction date” and a GL “posting date” can be days apart. Time zones can shift card swipes across midnight, especially for online tools and subscriptions.
A simple “prompt wrapper” you can reuse for every reconciliation run
Use this wrapper to keep outputs consistent across runs and across models. Paste it once, then paste one of the 15 prompts under it.
Reusable prompt wrapper (copy/paste):
You are a finance reconciliation agent. Your goal is to reconcile [SOURCE_A] to [SOURCE_B] using only the rows provided. Rules: do not invent data, do not assume missing fields, cite row IDs for every conclusion, and ask clarification questions when needed. Matching rules: allow a date window of [X] days, amount tolerance of [$Y] or [Z%], and vendor fuzzy-match only when other fields support it. Scoring: output a confidence score from 0 to 100 with a one-sentence reason. Outputs required: (1) Matches table with source row IDs, match type (1:1, 1:many, many:1), confidence, and notes, (2) Exceptions table with source row IDs, suspected cause, and next question, (3) Summary with match rate, total $ matched, total $ unmatched, and top 5 exception themes.
15 epic AI prompts for finance reconciliation agents (copy, paste, and run)
These prompts are tool-agnostic (ChatGPT, Claude, Gemini). They work best with file uploads. Use the placeholders like [BANK_CSV] and [GL_CSV] to keep your process repeatable.
Category 1: Transaction matching and categorization prompts (Prompts 1 to 5)
Prompt 1: Fuzzy-match vendor reconciliation (DBA names and memo noise)
Use when: vendor names don’t line up (DBA vs legal name, spelling, memo clutter). Paste/upload: [BANK_CSV] (date, amount, description, reference_id), [GL_CSV] (date, amount, vendor, gl_id, account). Prompt text: Reconcile [BANK_CSV] to [GL_CSV]. Normalize vendor names (remove suffixes, ignore punctuation, collapse whitespace). Only fuzzy-match vendors if amount matches within [$1.00] and date within [3] days. Output “Ready to Post” matches (confidence ≥ 90) and “Needs Review” matches (confidence 70 to 89) plus questions for anything below 70. Output: Matches table + exceptions table + short summary with match rate.
Prompt 2: Bank statement to GL auto-pairing (handles splits and bundles)
Use when: one bank line maps to multiple GL lines (or vice versa). Paste/upload: [BANK_CSV] and [GL_CSV] plus GL debit/credit indicator if you have it. Prompt text: Match [BANK_CSV] to [GL_CSV] allowing 1:many and many:1 matches. Use subset-sum style matching for same-day items within [5] days and variance up to [$2.00]. Provide confidence and list the component GL IDs for each grouped match. Separate results into Ready to Post (≥ 90) and Needs Review (70 to 89). Output: Match table with match type and component IDs, plus exceptions.
Prompt 3: Multi-currency normalization (FX rounding and settlement rates)
Use when: payouts settle in USD but invoices post in other currencies. Paste/upload: [BANK_CSV], [GL_CSV], and [FX_RATES_CSV] (date, from_ccy, to_ccy, rate) if available. Prompt text: Convert all amounts to [USD] using [FX_RATES_CSV] by transaction date, then reconcile [BANK_CSV] to [GL_CSV]. Flag FX rounding as “FX rounding” when variance ≤ [0.5%] and explain the math using row IDs and rates used. Never guess missing FX rates, ask for them. Output: Matches with converted amounts, FX notes, and an FX exceptions list.
Prompt 4: Orphaned transactions finder (unmatched bank or unmatched GL)
Use when: you need a clean “what’s missing” list fast. Paste/upload: [BANK_CSV], [GL_CSV]. Prompt text: Identify unmatched items on both sides after attempting standard matching (date ± [3] days, amount tolerance [$1.00], vendor normalization). For each orphan, propose likely causes (timing, fee netting, missing invoice, duplicate entry, wrong account) and ask the next best question to resolve it. Output: Two exception tables (unmatched bank, unmatched GL) plus themes.
Prompt 5: PO and invoice cross-check (light 3-way match)
Use when: you want a fast control check on AP flow. Paste/upload: [PO_CSV], [INVOICE_CSV], optional [RECEIPT_CSV], plus [GL_CSV] if you want posting validation. Prompt text: Cross-check PO to invoice (and receipt if provided). Flag price variances > [2%], quantity variances > [1 unit], missing receipts, and invoices posted to the wrong GL account. Output Ready to Post vs Needs Review, with confidence scores and row IDs for PO, invoice, and receipt used. Output: Variance table + exceptions + short posting recommendations (no assumptions).
Category 2: Discrepancy resolution and anomaly detection prompts (Prompts 6 to 10)
Prompt 6: Hidden bank fees and miscalculations (netted settlements)
Use when: deposits don’t equal sales totals because fees got netted. Paste/upload: [PROCESSOR_PAYOUT_CSV] (gross, fees, net, payout_id), [BANK_CSV], [GL_CSV]. Prompt text: Reconcile net payouts to bank deposits, then reconcile gross sales and fees to GL. Detect missing fee entries and fee rate changes. Output an exception list with likely root cause, recommended next step, and a suggested journal entry idea marked “Suggestion only, approval required.” Output: Exceptions + root cause + next step + JE suggestion (labeled).
Prompt 7: Duplicate payments and phantom invoices (near-match detection)
Use when: AP is busy and duplicates slip in. Paste/upload: [AP_PAYMENTS_CSV], [BANK_CSV], [GL_CSV]. Prompt text: Find duplicates and near-duplicates by vendor + amount + date proximity (within [7] days) and by invoice number similarity. Separate “Probable duplicate” (confidence ≥ 85) from “Possible duplicate” (70 to 84). For each, list evidence row IDs and suggest the next verification step. Include a suggested reversal entry idea marked approval required. Output: Duplicate list + evidence + next steps + suggestion.
Use when: batch payouts include refunds, disputes, and reserves. Paste/upload: [GATEWAY_BALANCE_TXNS_CSV], [BANK_CSV], [GL_CSV]. Prompt text: Reconcile gateway balance activity to bank payouts by payout_id and dates. Explain net vs gross, and break out refunds, chargebacks, and reserves. Flag mismatches over [$5.00] or [0.3%]. Produce an exception list, root cause hypothesis, and next action, plus JE suggestion ideas labeled approval required. Output: Payout tie-out table + exceptions + notes suitable for audit.
Prompt 9: Month-over-month variance explainer (top drivers, new vendors)
Use when: stakeholders ask why an account moved. Paste/upload: [GL_DETAIL_CURRENT_MONTH_CSV], [GL_DETAIL_PRIOR_MONTH_CSV]. Prompt text: Compare current vs prior month for account(s) [LIST]. Identify top 10 drivers by $ impact, call out new vendors, and separate timing shifts from real spend changes. For each driver, cite the GL row IDs. Output a short exec summary plus a drill-down table. Output: Exec-ready narrative + driver table + questions for missing context.
Prompt 10: Split payments across accounts (partials and mixed methods)
Use when: one invoice gets paid in chunks or via multiple rails. Paste/upload: [INVOICE_CSV], [BANK_CSV], [CARD_CSV], [GL_CSV]. Prompt text: Match invoices to payments across bank and card, allowing partials and mixed methods. Track remaining balance per invoice, and flag overpayments and unapplied cash. Provide a recommended next step for each exception and a labeled JE suggestion idea (approval required) for reclasses or unapplied balances. Output: Invoice-to-payment ledger + exceptions + next steps.
Category 3: Automated reporting and stakeholder follow-up prompts (Prompts 11 to 15)
Use when: you need receipts without chasing all day. Paste/upload: [EXPENSES_CSV] (date, amount, merchant, employee, expense_id, policy_limit). Prompt text: Draft short receipt requests for items missing documentation. Include transaction date, merchant, amount, expense_id, and a response deadline of [3 business days]. Keep tone polite and firm. Output in a table with employee, subject line, and message body. Output: Copy-ready email or Slack drafts.
Prompt 12: Daily reconciliation executive summary (match rate, top risks)
Use when: you want a tight daily heartbeat report. Paste/upload: Your day’s reconciliation outputs (matches and exceptions tables). Prompt text: Summarize today’s reconciliation: match rate, $ matched, $ outstanding, and top 5 risks. Add “What changed since yesterday” if yesterday’s summary is provided. Keep it under 150 words, plus a short bulleted risk list with row IDs. Output: One paste-ready update for Slack or email.
Use when: you need clean support for auditors or a controller review. Paste/upload: [EXCEPTIONS_TABLE_CSV], supporting documents list (invoice IDs, emails, approvals), and final resolution notes. Prompt text: Turn each exception into a narrative: what happened, evidence used (IDs only), who approved, and when it was resolved. Do not add facts not in the file. End each narrative with “Open items” if anything is pending. Output: One narrative per exception, ready to paste into workpapers.
Prompt 14: Accrual and reclass journal entry suggestions (with rationale)
Use when: close needs accruals and quick cleanups, but you want control. Paste/upload: [GL_DETAIL_CSV], [OPEN_INVOICES_CSV], optional [PAYROLL_CSV] or [CONTRACTS_CSV]. Prompt text: Suggest accrual and reclass entries based on patterns and timing, but label every entry as “Suggestion only, approval required.” For each, give rationale, affected accounts, period, and the exact source row IDs that triggered the suggestion. Ask questions when critical info is missing. Output: Suggested JE table + rationale notes + approvals reminder.
Prompt 15: Month-end close sign-off checklist (accounts tied to evidence)
Use when: you need a final control pass before sign-off. Paste/upload: Reconciliation summaries per account, open exceptions list, and approval log. Prompt text: Build a sign-off checklist by account: evidence attached, match rate, open items, owner, and required approvals. Highlight any account with high exceptions or missing evidence as “Do not sign off.” Provide a short close-ready status summary for leadership. Output: Checklist table + short leadership summary.
Make these prompts safe in real finance workflows
Automation can reduce stress, but only if you keep control. The safest pattern is simple: let the agent auto-match low-risk items, and route anything uncertain to a human reviewer. In March 2026, many teams are also moving to more frequent reconciliation runs (daily or continuous) so exceptions shrink before close week.
This is workable for solo operators on QuickBooks or Xero, and it also scales to ERPs. The trick is to put “seatbelts” around the prompts: tight thresholds, clear evidence requirements, and logging.
Privacy and data handling rules to follow before you paste anything
Before you upload files to any model or agent, reduce what you share. You usually don’t need full identifiers to reconcile.
Mask or remove:
Full bank account numbers (keep last 4 if needed)
Full card numbers (never include), CVVs, PINs
SSNs, tax IDs, DOBs
Full addresses when not needed for matching
Also, don’t hand over credentials. Never paste API keys, login links, tokens, or “live access” instructions into a chat. If you later connect tools, use least-privilege permissions and keep a clear off switch.
A lightweight rollout plan that proves value in one week
A one-week pilot beats a long “AI project” every time.
Pick one account (usually the main bank or highest-volume card). Track three numbers daily: match rate, time spent, and exception count. Tune thresholds, then expand only after results hold for three straight days.
A simple scorecard works:
Good: match rate climbs, exception count stabilizes, close prep time drops
Bad: match rate looks high but exceptions feel “hand-wavy” (tighten evidence rules)
By day 7, you should know if the agent saves time without adding risk.
FAQ (Frequently Asked Questions)
Will an AI reconciliation agent replace my accountant or bookkeeper?
No. It replaces the repetitive matching and first-pass triage. A human still approves postings and resolves judgment calls.
What’s the biggest reason reconciliation prompts fail?
Missing identifiers. If you don’t include row IDs, reference numbers, and clear dates, the agent can’t prove matches.
Can I use these prompts with QuickBooks or Xero?
Yes, as long as you can export CSVs. Start with bank-to-GL pairing, then add orphan detection.
How do I prevent “confident wrong” matches?
Require evidence: row IDs, rules, and confidence reasons. Also, don’t allow auto-posting below your cutoff.
Do I need a paid AI tool for this?
Not always. File upload support helps a lot, but the prompt structure matters more than the brand.
Conclusion
Late-night closes happen when matching stays manual and exceptions pile up. With AI prompts for finance reconciliation, you turn messy inputs into repeatable steps: match, score, explain, and route for approval. Start with the bank-to-GL auto-pairing prompt, then add duplicates and payout batching once you trust your thresholds. If you want it all in one place, grab the downloadable swipe file of all 15 prompts via email signup, then book a demo of the AI reconciliation tool to see the workflow run end-to-end.
5 AI Automation Hacks Your Competitors Use to Scale Business With AI Right Now
Your inbox is full. A lead asks for pricing, a customer wants an update, and someone replies to last week’s proposal with one new detail. You copy, paste, tag, and forward, then open the CRM and type the same info again. It feels productive, but it’s slow work.
Meanwhile, your competitors aren’t “better at email.” They’ve wired AI into the boring parts, so every customer signal gets routed, tagged, and acted on within minutes. No missed follow-ups. No messy spreadsheets. No “we’ll circle back” that never happens.
That gap turns into real money. Slower response times reduce close rates. Manual SEO work limits how much you can publish. Small errors add up, and your team pays for it with late nights.
Here are five less-talked-about automation moves that help you scale business with AI without hiring a bigger team. You’ll walk away with:
A clean workflow for intent-based keyword clustering
A safe way to publish at scale with programmatic SEO
Internal linking rules that compound rankings over time
Bulk metadata and technical fixes that lift clicks
A closed-loop system that routes leads and follow-ups on autopilot
Hack 1: Cluster keywords by meaning so you stop guessing what to publish next
Traditional keyword lists fail for one reason: they’re literal. You end up with 500 rows that “look different,” but they map to the same search intent. As a result, teams publish duplicate pages, split authority, and wonder why rankings stall.
Semantic clustering fixes that. Instead of grouping by matching words, you group by meaning and intent. In plain English, you’re sorting queries by what the searcher wants: to learn, compare, or buy.
The workflow is simple:
Export keywords from Google Search Console and your paid tools.
Cluster by intent, not by shared terms.
Choose one “main page” per cluster.
Assign supporting articles that answer side questions.
A lot of teams start with tool lists and never build a map. If you want a quick scan of what’s popular right now, this roundup of keyword clustering tools in 2026 is useful context. The goal isn’t the tool, it’s the outcome: one cluster equals one primary URL, with clear support content around it.
A simple intent map that turns one messy list into a publish plan
Here’s what a single theme can look like once it’s clustered:
Cluster theme
Searcher intent
Primary page type
Supporting content examples
AI CRM automation
Compare and buy
“Best tools” page
Pricing guide, setup checklist, templates
AI CRM automation
Learn
“How to” guide
Workflows by industry, pitfalls, examples
AI CRM automation
Evaluate
“X vs Y” comparison
Alternatives, feature matrix, migration tips
AI CRM automation
Do it now
Templates
Email triage rules, CRM field mapping
A quick way to keep this tight is to set three rules: label intent, assign one primary URL, and score priority (impact versus effort). The most common mistake is publishing two pages that answer the same question with different titles. That’s content cannibalization with extra steps.
The competitor move most teams miss: build clusters from real SERP patterns
Competitors don’t cluster in a vacuum. They look at what already ranks and mirror Google’s current grouping.
Try this first: grab 20 to 50 competitor URLs that rank for your core offers, then feed those pages into your clustering process. Extract headings and repeated subtopics, then merge that with your keyword list. You’ll spot gaps fast, especially “comparison” and “pricing” intents that teams skip because they feel too close to sales.
The win is alignment. When your content map matches the SERP’s natural buckets, you spend less time guessing and more time shipping.
Hack 2: Programmatic SEO that ships thousands of pages without sounding like a robot
Programmatic SEO is not “publish 10,000 AI pages.” It’s a template system fueled by structured data, where each page targets a real, repeatable need.
Think of page types like:
“[Service] in [city]” pages for agencies
“[Tool] alternatives” pages for SaaS
“Best [category] for [industry]” pages
Integration directories and partner pages
Competitors scale this because the template does the heavy lifting and the dataset keeps each page grounded in specifics. If you want a practical reference point for the tooling and common setups, this guide on programmatic SEO tools lays out the categories teams use in 2026.
A safe pipeline looks like this:
Pick one repeatable page type tied to revenue.
Build a dataset (sheet or CSV) with real fields.
Write a page blueprint with strict section rules.
Generate drafts with AI, then review a sample set.
Publish in batches, measure, and iterate.
This is how you scale business with AI while keeping headcount flat.
The “template plus dataset” formula that makes pages feel custom
A template only works when each page has “fresh air” in it. Require unique fields per page, such as local examples, integration steps, pricing notes, common objections, and FAQs.
One simple outline for a “[city] + service” page:
Who the service is for in that city
Common problems and typical timelines
Local proof points (industries served, constraints, compliance)
A short process section (3 to 5 steps)
FAQs tailored to that city
One clear next step (call, quote, audit)
Guardrails matter. Ban filler phrases. Require at least two page-specific facts from your dataset. Add a validation step before bulk publishing.
Quality control at scale: how to prevent thin pages and duplicate content
Competitors avoid penalties by treating QA like a production line. Start with deduping titles and meta descriptions. Next, run a similarity check across drafts. If pages look too close, hold them back.
A simple rule works well: if a page doesn’t target one clear intent cluster, it doesn’t ship. Also, don’t be afraid to noindex weak pages until they meet your standard. That’s better than flooding your site with near-duplicates that hurt trust.
Hack 3: Automated semantic internal linking that pushes your best pages up
Internal links are your site’s road signs. They tell Google what matters and help people find the next answer without bouncing back to search.
Manual internal linking breaks as your site grows. People forget older posts, link to whatever they remember, and over-link the same “money page” with the same anchor text. Competitors automate link suggestions based on meaning, not exact words.
That semantic layer is the difference. You can link “CRM auto-tagging” to “lead routing rules” even when the keywords don’t match.
If you’re evaluating tooling, this write-up on AI internal linking tools is a good overview of what’s available in 2026. The main point is the workflow: clusters first, hubs second, then automated suggestions with human approval.
A safe linking rule set your team can apply in under an hour
Keep it boring and consistent:
Add 2 to 5 contextual links per article.
Link up to the hub page, then sideways to sibling pages.
Vary anchor text naturally, based on the sentence.
Don’t force links where the reader wouldn’t click.
Link to the best next answer, not the page you want to rank.
Measure impact in plain metrics: crawl frequency, time on page, and hub rankings. If hubs rise and new pages index faster, it’s working.
The overlooked win: post-publish link audits that compound results
The compounding effect comes from one habit: every new page should strengthen older pages.
Set a monthly routine. Scan new content, add missing cluster links, fix broken links, and update anchors that no longer match the target page’s purpose. Also, keep key pages within a few clicks of the homepage by adding hub pages that act like category rails.
You don’t need perfection. You need repetition.
Hack 4: Bulk metadata and technical SEO fixes that raise clicks without extra traffic
Your title tag and meta description are your search ad. Even if you rank, weak metadata can bleed clicks to competitors.
Doing this manually is a trap. Teams tweak one page, then forget the other 500. Competitors generate metadata in bulk, but they do it with intent-based patterns.
They separate rules for:
How-to pages (promise a clear outcome)
Pricing pages (make it obvious what’s included)
Comparisons (help the reader choose)
Alternatives (name who it’s for and why)
On the technical side, they also automate checks for broken links, redirect chains, canonical mistakes, sitemap issues, and schema errors. For a sense of what modern “AI-assisted technical SEO” tooling looks like, this overview on AI tools for technical SEO captures the direction the market is moving.
Write titles that match what the searcher wants, not what you want to say
Here are simple formulas that work because they’re clear:
Best X for Y (2026)
X Pricing, Plans, and What It Includes
X vs Y: What to Choose
How to X (Steps, Time, Cost)
A quick check before you publish: does the title say what the page delivers, in plain words? If not, fix it. Clarity beats cleverness.
Automate technical checks so small issues do not quietly kill growth
Set lightweight alerts for the stuff that actually hurts:
Index coverage changes
Sudden traffic drops by page group
Duplicate canonicals
Slow templates after site updates
Schema errors after plugin changes
Use a simple cadence: weekly alerts, monthly deep audit, then a “fix first” list. Start with indexing, then cannibalization, then speed, then schema. This order keeps you focused on the biggest constraints.
Hack 5: Plug AI into the whole marketing lifecycle so nothing falls through the cracks
SEO automation is only half the story. The real advantage comes when content, leads, and follow-up run as one system.
Competitors build a closed loop:
Intent research drives content plans.
Content drives form fills and inbound emails.
AI classifies intent and creates clean CRM records.
Follow-ups trigger automatically, with human review.
Outcomes feed back into what to publish next.
That’s how they scale business with AI without adding layers of coordinators.
If you’re comparing platforms that bake AI into CRM workflows, this list of AI CRM software for 2026 is a solid starting point. The key is not the brand name. It’s the behavior: faster routing, cleaner fields, and fewer dropped balls.
A “closed loop” workflow from search intent to booked calls
Here’s an end-to-end example you can implement without heavy engineering:
A visitor lands on a comparison page and fills out a form. AI reads the message and labels it (pricing, support, enterprise, or partner). Then it extracts fields like company size, timeline, budget range, and the product they mentioned. Next, it creates or updates the CRM record, assigns an owner, and drafts a reply that matches the intent. Finally, it schedules a follow-up task if the lead doesn’t respond.
Track three KPIs for proof: time to first response, lead-to-meeting rate, and cost per published page. When response time drops, meeting rates usually rise.
If a lead waits 24 hours, you’re competing on luck. If they get a tailored reply in 5 minutes, you’re competing on process.
Start small: one automation per week that saves real hours
A simple rollout plan keeps momentum:
Week 1: Build your intent-based keyword cluster map.
Week 2: Launch one programmatic template, publish 50 pages.
Week 3: Apply semantic internal linking rules, run a link audit.
Week 4: Refresh metadata in bulk for your top pages.
Week 5: Automate lead routing from email and forms into your CRM.
One caution: don’t automate a broken process. Standardize the steps first, even if it’s just a one-page SOP.
FAQ
Are these automations only for big teams?
No. Smaller teams benefit more because they feel the time savings faster. Start with one workflow, prove it, then expand.
Will programmatic SEO get my site penalized?
It can if you publish thin, duplicate pages. Use a real dataset, strict templates, and a sample QA review before bulk publishing.
Do I need to replace my writers or SEO team?
You need to shift their work. Let AI handle clustering, drafts, linking suggestions, and bulk metadata. Keep humans on strategy, editing, and proof.
What’s the fastest hack to implement this week?
Keyword clustering by intent. It removes guesswork and stops you from writing duplicate content.
How do I know automation is paying off?
Watch cycle time. Content production speed, indexation speed, and lead response time all move quickly when the system works.
Conclusion
These five hacks all point to the same outcome: speed with fewer errors. Semantic clustering gives you a publish plan, programmatic SEO multiplies output safely, internal linking compounds authority, bulk metadata boosts clicks, and closed-loop lead routing keeps revenue moving. Your competitors aren’t smarter, they’re just automated.
If you want to keep pace, pick one hack and implement it this week. Then sign up for the weekly newsletter for practical AI marketing updates, and download the “AI Automation Blueprint” to get the exact tools and workflows to scale.
Master Customer Support Escalation With High-Impact AI Prompts (Agentic Workflow Bundles for 2026)
A client emails at 7:12 a.m., “Our traffic is down 38%. What did you change?” Meanwhile, chat pings nonstop, phones light up, and a dashboard alert shows an outage in reporting. Emotions rise fast, and your team has to respond the same way every time, even when you’re short staffed.
That’s where customer support escalation prompts earn their keep. In plain terms, they’re ready-to-use instructions that tell an AI agent (or a human) what to say and do next, when to keep troubleshooting, and when to hand off to a specialist. Good prompts don’t just generate a reply. They guide a safe workflow. Grab your bonus 25 prompt starter kit below to get you started!
This post shares a simple framework, the most requested prompt bundle types for agentic workflows in 2026, and a two-week rollout plan. The goal is practical: lower time-to-resolution, higher CSAT, fewer policy mistakes, and calmer clients, especially when SEO results swing and retention is on the line.
Why AI-driven escalation workflows help keep clients from churning (especially in SEO)
In SEO, clients judge you by outcomes they can see. Rankings move, traffic shifts, and suddenly your support queue becomes a pressure cooker. When your team answers those tickets with mixed tone and mixed facts, clients don’t just get annoyed, they lose trust.
Mishandled escalations create quiet costs:
Refund demands that didn’t need to happen
Chargebacks and contract disputes
Negative reviews that hit pipeline
Lost renewals because “support felt chaotic”
Team burnout from repeated back-and-forth
Manual responses fail under stress because people skip steps. Someone forgets to ask for dates. Someone else guesses a cause. A third person promises a timeline they can’t control.
Agentic workflows fix this by turning escalations into a repeatable path. The prompts tell the AI to (1) check facts from the ticket and account, (2) ask the right missing questions, (3) follow policy, then (4) escalate with a clean summary when needed. If you’re building the rules from scratch, it helps to review common escalation triggers and handoff patterns, like the ones outlined in AI escalation rules and handoff triggers.
The “calm, clarify, commit” loop that keeps anxious clients engaged
Think of anxious clients like passengers during turbulence. They don’t need a speech, they need a steady voice and a plan.
Calm means naming the emotion without arguing with it. Example lines for SEO panic tickets:
“I hear how urgent this feels, especially with leads on the line.”
“Thanks for flagging this quickly. I’m going to get the right details first.”
Clarify means separating facts from guesses.
“What date and time did you first notice the drop?”
“Which pages or landing pages are most affected?”
“Did anything change on your site, ads, or tracking last week?”
Commit means next steps with timelines, without overpromising.
“Here’s what I can confirm now, and what needs investigation.”
“You’ll get an update by 2 p.m. ET, even if the update is ‘still investigating.’”
That loop buys you time and protects trust.
When AI should escalate right away vs. keep troubleshooting
Not every tough ticket needs a human. Still, some do, and waiting too long makes the handoff worse.
Here’s a simple decision guide you can bake into your prompts:
Signal
Keep troubleshooting
Escalate now
Customer tone
Neutral, confused
Angry, abusive, or caps-heavy
Risk level
Low business impact
VIP account, launch day, or high revenue
Policy pressure
Simple billing question
Refund demand beyond policy, chargeback threat
Confidence
High, facts available
Low confidence, missing access, unclear root cause
Safety
No privacy risk
Legal, security, data loss, or compliance concern
One hard rule for SEO cases: the AI must not invent causes for ranking drops or promise recovery dates. If the customer asks, “Will we be back by Friday?”, the safe answer is a committed investigation timeline, not a prediction.
The prompt bundle types support leaders ask for most in 2026
Support leaders don’t want one magic prompt. They want bundles that match real workflows: respond, verify, troubleshoot, and hand off with context. If you’re mapping an agentic setup, it helps to see how support teams structure multi-step AI workflows, like the patterns described in agentic AI workflows for support leaders.
Each bundle below should specify three things:
Inputs (what the AI must read first): ticket history, account tier, policy, incident status, recent changes
Outputs (what the AI must produce): next-best action, response draft, and an escalation brief when needed
Boundaries (what the AI must never do): guess root cause, promise refunds, share internal tools, or skip privacy checks
Damage control prompts for ranking drops, traffic loss, and “what did you change?” emails
What it’s for: turning a panic message into a controlled investigation. Inputs needed: affected pages, dates, GA/GSC access status, last known deploy, recent content changes, tracking changes. Outputs required: a customer-facing message, an internal checklist, and an escalation note to the SEO lead.
The response prompt should force categories, not conclusions. For example: algorithm update, technical change, content change, tracking issue, or external factor. It should also require one sentence that protects trust: “I don’t want to guess at a cause before we verify the data.”
Technical delay explainer prompts that make complex SEO work easy to understand
What it’s for: explaining why crawl, index, migrations, hreflang, canonicals, log analysis, and Core Web Vitals take time. Inputs needed: current stage, blockers, what’s already complete, and what’s waiting on third parties. Outputs required: a simple explanation with a timeline that labels uncertainty.
Require the AI to use three labels in the timeline: confirmed, likely, unknown. Then add a teach-back question: “Can you reply with your top priority page or goal, so I confirm we’re aligned?”
Policy-safe billing and refund escalation prompts that reduce back-and-forth
What it’s for: billing disputes that can turn hostile fast. Inputs needed: invoice ID, plan, renewal date, prior credits, refund policy, identity checks. Outputs required: a policy-safe reply plus a clean escalation summary if the ask is out of bounds.
Make the workflow restate the charge, then offer only allowed options (credit, partial refund, plan change). Include a required line that prevents accidental promises: “I can’t confirm a refund until billing reviews your account details.”
Outage and incident prompts that switch the team into status mode fast
What it’s for: downtime, bugs, data delays, reporting outages, or API incidents. Inputs needed: current incident status, impacted features, affected regions, workaround options, last update time. Outputs required: a customer message plus an internal incident note with severity and business impact.
Prompts should forbid unverified ETAs. Instead, they set a next update time. Escalation triggers should include “no ETA available,” repeated follow-ups, threats to cancel, and high-impact accounts.
Tone control and de-escalation prompts for angry customers and public review threats
What it’s for: keeping your brand calm while holding boundaries. Inputs needed: message history, sentiment level, previous offers, policy limits. Outputs required: a de-escalation reply, one-sentence summary, and “what I can do right now.”
Add a special path for review threats. The AI should acknowledge, offer a clear next step, and escalate with urgency. If you want a cautionary view on how chat can quietly damage CX when handoffs fail, read AI chat agents risks and buyer guidance.
A good escalation prompt doesn’t “win” an argument. It reduces heat, protects facts, and moves the ticket forward.
Soft CTA: If you want a ready-made starting point, offer a PDF download called “Swipe File of 25+ Customer Support Escalation Prompts” in exchange for an email. Keep it optional, and position it as a time-saver for your next busy week.
The Escalation Neutralization Framework to prevent mistakes and hallucinations
When tickets get tense, the AI’s biggest risk is simple: sounding confident while being wrong. Your framework should make “I don’t know yet” acceptable, as long as it comes with a plan.
The safest approach is consistent empathy, strict facts, and fast handoffs. That means your prompts must inject context in a controlled way, such as ticket history, account tier, the last action taken, and the exact policy text that applies. Anything else stays labeled as unknown.
To tighten handoffs, many teams formalize a hybrid model where the AI does triage and drafting, then humans handle high-risk judgment calls. This breakdown is explained well in a hybrid AI-human handoff framework.
A simple workflow: detect risk, gather facts, choose a safe path, then hand off with a brief
Gather facts: ask only for missing info, and avoid repeat questions.
Choose a safe path: recommend a resolution path with a confidence tag (high, medium, low).
Hand off with a brief: produce an escalation packet a specialist can act on quickly.
That escalation packet should always include: issue summary, timeline, account details, steps tried, exact customer ask, sentiment, and the recommended next action.
Guardrails that keep the AI honest in high-stakes tickets
Guardrails stop small mistakes from turning into big promises. Add rules like these:
Name the source of any claim (policy text, status update, account data).
Never guess root cause for rankings, outages, or data loss.
Never promise refunds or recovery dates.
Don’t mention internal tools or private processes.
Always offer a human option, especially when emotion is high.
Run privacy checks before sharing account details.
Red flags that should force escalation: legal threats, security concerns, data exposure, safety issues, or claims of financial harm.
Step-by-step rollout guide for support teams (from swipe file to daily use)
A prompt library doesn’t work if it lives in someone’s docs folder. It needs structure, ownership, and a short feedback loop.
Start small. Pick a few high-volume escalation types, pilot them, and score outcomes. Then expand. Track metrics that show real impact: CSAT after escalation, time-to-resolution, recontact rate, containment rate, policy compliance, and an escalation quality score (did the brief include what Tier 2 needed?).
Build a shared prompt library that matches your brand voice and escalation rules
Organize your library by scenario and tier (Tier 1, Tier 2, Tier 3). Each prompt bundle should have a clear name and required fields for inputs.
Also add a brand voice layer:
Approved phrases your team likes
Banned phrases that sound defensive
A tone rule for conflict (calm, direct, no blame)
When new hires join, they don’t “learn vibes.” They follow the same playbook.
Launch in two weeks with testing, coaching, and scorecards
A simple 14-day plan works well:
Days 1 to 3: pick 3 escalation types (billing, outage, ranking drop).
Days 4 to 7: pilot with a small group, then review transcripts daily.
Days 8 to 10: tune prompts based on misses (missing questions, policy slips, tone issues).
Days 11 to 14: expand to more agents and add a weekly calibration.
Use a scorecard with five items: empathy, clarity, policy safety, next steps, handoff quality.
Change management matters. Involve senior agents early, create quick references, and set a clear human override process so nobody feels trapped by the AI.
FAQ
What are customer support escalation prompts, in simple terms?
They’re instructions that guide what to say, what to check, and when to hand off. The best ones produce both a customer reply and an internal brief.
Do escalation prompts replace Tier 2 or Tier 3?
No. They reduce noise and improve handoffs. Specialists still handle judgment, edge cases, and high-risk situations.
How do you stop the AI from making things up during SEO scares?
Force “facts first.” Require sources (GSC data, incident status, account notes), label unknowns, and ban root-cause guesses and date promises.
What should the AI include in every escalation handoff?
Issue summary, timeline, steps tried, exact customer request, account tier, sentiment level, and a recommended next action.
Which metrics show the rollout is working?
Watch CSAT after escalations, recontact rate within 7 days, time-to-resolution, and policy compliance. Also audit the quality of escalation briefs.
Conclusion
When ticket volume spikes and emotions run hot, the best customer support escalation prompts work as agentic workflows, not one-off scripts. They detect risk, gather facts, respond with empathy, and escalate with a clean brief that saves everyone time.
If you want a fast start, offer the “Swipe File of 25+ Customer Support Escalation Prompts” PDF as an optional download. Then, when you’re ready, invite stakeholders to book a demo of your AI-powered support platform so they can see the workflows in real tickets. Attached below is a swipe file of 25 prompts to get you started. You can use these or change them to work how you want…
SWIPE FILE:
Prompt engineering for business: 25 Prompts to copy and paste Classifies queries, routes to specialized agents (e.g., tech vs. billing), summarizes cases with context, and escalates only edge cases:
1. Develop a simulation scenario for the Master Triage and Routing Orchestrator: A customer reports a persistent login error on their subscription service, stating they have tried all troubleshooting steps and are extremely frustrated. Provide the exact input query and predict the orchestrator’s complete JSON output, including classification, sentiment, summary, and routing decision, ensuring high frustration leads to escalation.
2. Generate a set of 10 diverse customer inquiries specifically tailored to train the Master Triage and Routing Orchestrator in accurately identifying ‘Billing/Account’ related issues. Include examples of payment failures, subscription cancellations, and refund requests, with varying sentiment levels.
3. Draft a comprehensive prompt for configuring the Master Triage and Routing Orchestrator to recognize and prioritize queries originating from specific enterprise clients. If a query contains a designated ‘Enterprise_Client_Tag’, it should be automatically routed as an ‘EDGE_CASE’ regardless of initial sentiment, ensuring rapid human intervention.
4. Construct a test case for the orchestrator: A user reports that their recently purchased digital asset is corrupt, making it unusable. They also mention that their previous support ticket for a similar issue was never resolved. Design the input query to reflect this complexity and high frustration, then outline the expected JSON output with a focus on ‘escalation_required’.
5. Create a prompt instructing the Master Triage and Routing Orchestrator to expand its intent classification capabilities. Add ‘Feature Request’ and ‘Product Feedback’ as new categories, and provide initial keyword lists and example queries for each to aid in accurate classification.
6. Develop a prompt for the orchestrator to process incoming feedback from public review platforms (e.g., App Store, Google Play). The orchestrator should extract key sentiment, identify common technical issues or feature gaps, and route these insights as ‘General Inquiry’ or ‘Technical Support’ for product team review.
7. Design a comparative analysis prompt for the orchestrator: Provide two distinct customer queries, one describing a ‘General Inquiry’ about product functionality and another detailing a ‘Technical Support’ issue with the same feature. The orchestrator should highlight the differentiating factors in its classification and routing decisions.
8. Formulate a prompt for the Master Triage and Routing Orchestrator to perform a meta-analysis on a sequence of five related customer interactions over a week. The goal is to identify the overarching problem, consolidate the core issues into a single summary, and propose a definitive routing decision or ‘EDGE_CASE’ if the situation remains unresolved.
9. Generate a prompt to enhance the orchestrator’s filtering capabilities. Instruct it to identify and categorize irrelevant or spam-like inputs as ‘Junk/Spam’, routing them to a dedicated queue and ensuring these do not negatively impact sentiment analysis or trigger false escalations.
10. Create a prompt for the orchestrator to compile a daily performance summary. This report should detail the volume of queries per category, the average sentiment score for each, and the total count of ‘EDGE_CASE’ escalations, presented in a structured format suitable for management review.
11. Simulate a complex customer query for the orchestrator: A user requests a partial refund for a digital course they couldn’t complete due to persistent platform errors, which they detail extensively. This involves both ‘Billing/Account’ and ‘Technical Support’ elements. Predict the orchestrator’s routing and escalation decision.
12. Craft a prompt for the orchestrator to handle a highly urgent ‘Technical Support’ query: A user reports critical service downtime impacting their business operations, expressing extreme urgency and frustration. The prompt should ensure immediate identification of high sentiment and mandatory ‘EDGE_CASE’ escalation.
13. Develop a prompt to configure a new rule for the Master Triage and Routing Orchestrator: Implement an auto-escalation trigger for any query containing the keywords ‘critical outage’, ‘data loss’, or ‘legal dispute’, assigning an automatic sentiment score of 9 and routing as ‘EDGE_CASE’ regardless of other factors.
14. Generate a prompt to test the Master Triage and Routing Orchestrator’s multilingual processing capabilities. Provide a customer query in a non-English language (e.g., German or French) concerning a ‘Technical Support’ issue, and verify that the orchestrator accurately performs all triage steps.
15. Formulate a prompt for the orchestrator to identify and appropriately route queries related to data privacy requests, such as GDPR or CCPA inquiries. These should be categorized as ‘General Inquiry’ but also flagged as ‘EDGE_CASE’ for review by a specialized ‘Legal/Compliance’ department due to their sensitive nature.
16. Design a prompt for the orchestrator to process customer feedback from live chat transcripts. It should be capable of extracting intent and sentiment from conversational language, including common abbreviations and emojis, before routing the underlying issue to the relevant department.
17. Craft a prompt to instruct the orchestrator on managing follow-up inquiries. If a query references a previous ticket ID or ongoing issue, the orchestrator should attempt to link it to the original conversation and, if the user expresses renewed frustration, consider an ‘EDGE_CASE’ escalation.
18. Provide a prompt for the orchestrator to produce a weekly ‘EDGE_CASE’ analysis report. This report should list all queries escalated as ‘EDGE_CASE’, including their contextual summary, sentiment score, and the primary reason for escalation, aiding in identifying systemic issues.
19. Simulate a customer query for the orchestrator that is purely informational: A user asks for best practices on integrating a specific third-party tool with the digital product. This is not a technical problem. How would the orchestrator classify this ‘General Inquiry’ and route it effectively?
20. Create a prompt to rigorously test the Master Triage and Routing Orchestrator’s ability to handle highly ambiguous or vague customer inputs. Provide a query that lacks clear intent or specific keywords, and evaluate if the orchestrator defaults to a logical category, or correctly identifies it as an ‘EDGE_CASE’ due to ambiguity.
21. Contextual Summary: User reports inability to log in to their account. Original query: ‘I can’t access my dashboard, it just says “invalid credentials” even though I’ve reset my password twice.’
Contextual Summary: Customer states their new feature isn’t appearing after an upgrade. Original query: ‘I upgraded to the Pro plan yesterday, but I still don’t see the advanced analytics module. What’s wrong?’
22. Contextual Summary: User is experiencing slow application performance. Original query: ‘My software is running incredibly slow today. It’s almost unusable. How can I fix this?’
23. Contextual Summary: Client unable to upload files, receiving an error. Original query: ‘I keep getting an error message when I try to upload my documents. It says “file format not supported” but it’s a standard PDF.’
24. Contextual Summary: User needs assistance setting up email integration. Original query: ‘I’m trying to connect my Gmail account to your platform, but the instructions aren’t clear. Can you walk me through it?’
25. As the Specialized Resolution Agent (Technical Engineer), a user’s critical system functionality is down, requiring a server-side database override to restore service. Detail the ‘Senior Specialist Handover’ document, including the ‘Attempted Resolutions’ (e.g., initial diagnostics, user-side checks) and the ‘Specific Blockage’ (inability to perform database override).
I hope you find these prompts to be useful and please let me know how they worked for you and I will send you an additional 50 workflow prompts pdf. at no cost to you. Thanks again!
Fix Your AI Strategy: Context Engineering Delivers Instant Results
A marketer asks an LLM to write a product page. It confidently states the warranty is “lifetime.” Your policy says “2 years.” No one told the model the policy, so it filled the gap with a familiar pattern.
That’s the real story behind most “hallucinations.” The model isn’t failing because it’s “not smart enough.” It fails because it doesn’t have the right facts at inference time, or the facts are present but buried under noise.
Many teams respond by tweaking prompts, adding lines like “be accurate” or “don’t make things up.” That’s a closed-book exam with stricter rules. The higher-impact shift is context engineering, designing what the model sees before it writes a single word. This post breaks down what context engineering is, why it produces fast wins for AI SEO programs, and how to apply a practical checklist, a template, and a workflow that reduces errors without slowing your calendar.
The 3 fatal flaws of standard AI SEO strategies (and why they keep producing generic fluff)
Most AI SEO problems are system problems. They come from what the model can see in its context window, not from the writer’s skill. If the model starts with thin, messy, or inconsistent inputs, it will produce thin, messy, or inconsistent pages.
Flaw 1: Prompt-only fixes hide the real problem, missing ground truth
Prompting is useful, but it can’t replace missing sources. Think of the model like a strong student. A strong student still struggles on a closed-book test when you ask for exact figures and policies.
“Be accurate” fails for the same reason. If the model can’t see your current pricing rules, approved claims, or definitions, it guesses. When it guesses, it often sounds confident, which is worse than being unsure.
A better prompt can improve structure and tone. It can’t conjure your internal facts. That’s why teams are moving away from treating prompt text as the control plane and toward treating context as the control plane. Elastic summarizes that shift clearly in its overview of context engineering vs. prompt engineering.
Flaw 2: Copy-paste context dumps overload the window and bury key facts
Teams often paste everything into one prompt: a style guide, a competitor export, a product spec, a brief, a list of keywords, and a transcript. The result is predictable. Important facts get pushed into the middle, conflicting instructions show up, and the model “forgets” the one line that mattered.
This is signal vs. noise. Every extra paragraph competes for attention. If the context includes five versions of a feature description, the model may blend them into a new sixth version.
If you want fewer hallucinations, stop adding more text. Start adding better text.
Flaw 3: No repeatable context system means outputs drift across pages and weeks
Even if one page comes out fine, the program usually breaks at scale. Without a shared context layer, each writer or agent invents its own “truth” each time. That causes drift:
Brand voice changes across a cluster.
Product claims conflict between pages.
Headings vary, which breaks templates and internal linking patterns.
Updates lag because there’s no single place to change “what’s true.”
When leadership says, “Why is this page claiming X when legal says Y?” the answer is often simple: the model never had access to the approved source at the moment it generated the copy.
Defining context engineering: why priming beats prompting for reliable outputs
Context engineering is the discipline of deciding what the model gets to “read” before it answers, then arranging that material so the most important truths stay visible and usable. It is less about clever wording and more about curation, ordering, structure, and timing.
A practical definition that maps well to production work is: selecting, structuring, and injecting the minimum set of facts, rules, examples, and tool outputs that the model needs to complete a task safely.
Teams often treat this as an app architecture problem, not a writing problem. Context becomes a built asset, versioned, reviewed, and reused. Context Studios frames it as designing the context “by design,” not as an afterthought in building reliable LLM systems by designing the context.
What context engineering is in plain terms (the model’s “read this first” package)
In practice, a “read this first” package usually includes:
Retrieved source snippets (RAG) from docs, help centers, or databases
Brand rules and voice boundaries
User intent notes (what the reader needs to decide or do)
Verification steps (what to cite, what to flag as unknown)
Just-in-time retrieval matters because freshness matters. Policies, pricing, and feature sets change. If the model can’t see the latest state, it will write yesterday’s truth.
Prompt engineering vs. context engineering: a quick decision guide
Use this table to decide where to spend effort.
Situation
Better prompt is usually enough
Context engineering is required
Low-risk copy
Social posts, brainstorming angles
Regulated or legal claims
Fact sensitivity
Generic topics with stable facts
Pricing, warranties, SLAs, security
Workflow length
One-shot output
Multi-step programs, agents, clusters
Consistency needs
One page, one time
Dozens of pages over weeks
Prompts still matter, but prompts are only one slice of the context window. If the model can’t see the facts, your best prompt is still a closed-book test.
Why hallucinations happen at inference time (and why “bigger models” don’t solve it)
During generation, the model predicts the next token based on patterns and whatever text is present. Two failure modes show up most:
Empty context: the model lacks the needed facts, so it guesses.
Messy context: the model sees conflicts or outdated snippets, so it blends them.
Bigger context windows help, but they don’t remove the need to curate. Long prompts can still lose critical details “in the middle,” especially when many passages compete for attention. Research and mitigation work around this “lost-in-the-middle” issue continues to evolve, including recent studies such as What Works for ‘Lost-in-the-Middle’ in LLMs?.
The 5-point contextual checklist for every SEO asset (before the model writes a word)
Context engineering becomes simple when you treat it like pre-flight checks. Before any draft, confirm five things. Each one is measurable, and each one reduces guessing.
1) Objective and audience: one page, one job, one reader
Start with a single page objective. Inform, compare, or convert. Then name the reader and their pain. “IT director evaluating risk” produces different content than “operator trying to fix an error.”
Keep this short. Two sentences often beat two paragraphs. Also define constraints early, like reading level, audience region, and what the page must not promise.
A compact “success looks like” list helps the model stay on task. Three bullets is enough. The goal is focus, not decoration.
2) Ground truth pack: the minimum facts the model must not get wrong
This pack should include only facts you will defend in public:
Approved product facts and naming
Policy language (refunds, warranties, support hours)
Pricing rules (what can be stated, what must be linked)
Definitions for key terms
One or two source snippets per critical claim, with a last-updated date
Freshness is part of truth. If a snippet is older than your release cycle, mark it “stale.” When sources disagree, define the tie-breaker (for example, “Policy doc overrides blog posts”).
3) SERP and competitor reality: what must be covered to be useful
SERP context doesn’t mean pasting ten competitor pages. It means summarizing patterns:
The dominant intent (how-to, comparison, pricing, troubleshooting)
The must-answer questions that show up repeatedly
The common misconceptions that lead to bad decisions
Add one small but powerful boundary: “what we will not claim.” This reduces risky overreach, especially when competitors exaggerate.
4) Structure and formatting rules: make the output easy to publish and reuse
A good draft that breaks your pipeline is still a failure. Define the output contract:
Required sections and heading style
Internal link targets by slug or page name
Voice rules (what tone, what not to do)
If needed, schema fields to populate (FAQ items, pros-cons, specs)
Structured inputs reduce ambiguity. JSON works well for facts and constraints. Markdown works well for outlines and examples. The best systems use both: JSON for the truth pack, Markdown for the writing plan.
5) Token budget and noise control: prune, rank, then retrieve
More context is not always better context. Use a simple order:
Prune irrelevant text.
Rank what remains by task relevance.
Retrieve extra facts only when needed.
Many teams set starting token targets by asset type, then tune from there. For example, a short blog might carry a 600 to 1,200 token context pack, while a pillar page might justify 1,500 to 3,000. The number matters less than the habit: tight context, clear priorities, and retrieval on demand.
Template: the authority-builder prompt structure that makes context usable
A context-engineered prompt reads like a spec, not a chat. Keep the parts separated so you can swap context blocks without rewriting instructions.
Ordering matters. Put the ground truth early. Put style rules after truth. Put the outline last so it doesn’t crowd out facts.
Built-in self-checks that reduce false claims without adding fluff
Add strict checks like these:
“For any numeric claim, quote the source snippet or mark it UNKNOWN.”
“If a required input is missing, ask one question before drafting.”
“If sources conflict, follow the tie-breaker rule, then cite the chosen source.”
This is how you get safer outputs without turning the draft into cautious filler.
Workflow: integrating context engineering into your content calendar (without slowing the team)
Context engineering should speed teams up after the first week. The key is ownership and reuse.
Build a shared context library: brand truths, product facts, and reusable snippets
Set up a small repository with versioning:
Brand voice rules (stable)
Product facts by product line (changes with releases)
Claim language by category (security, performance, compliance)
Definition glossary (prevents term drift)
Assign owners. Set a review cadence aligned to releases. Enforce a single source of truth rule, so every agent and writer pulls from the same library.
Also set privacy boundaries. If a context pack includes customer data, you need redaction and access controls before it touches an LLM.
Just-in-time retrieval for writers and agents: RAG, re-ranking, and pruning
RAG works best when retrieval is precise and snippets are short. A common flow is: search, re-rank, insert top passages, then generate.
Hybrid retrieval helps. Combine keyword search for exact terms (like policy names) with vector search for semantic matches, then re-rank. For a practical overview of production RAG patterns, see Comet’s Retrieval-Augmented Generation (RAG) guide.
Quality gates and metrics that show instant results
You don’t need perfect evaluation to see improvement. Track a small set:
Hallucination rate via spot checks on “must-not-be-wrong” claims
Revision cycles per asset
Time-to-publish
Token cost per published page
Formatting errors that break publishing
Pilot on one content cluster for two weeks, then expand. The gains usually show up in fewer rewrites and faster updates when facts change.
Case study: 300% increase in keyword velocity via contextual injection
This is an anonymized enterprise rollout from a mid-market B2B SaaS team.
The starting point: good prompts, weak context, and content that didn’t stick
The team had solid prompts and a capable model. Still, pages came out generic. Intros repeated across posts. Feature descriptions drifted between articles. A product rename created weeks of cleanup, because older drafts had baked in the old terms.
Editors spent their time fixing specifics, not improving the argument. Internal links also looked random, because every draft invented its own cluster structure.
The fix: add a ground truth pack plus SERP intent notes for each cluster
They built per-cluster context packs:
A short truth pack with approved naming, feature bullets, and policy snippets
SERP intent notes that listed must-answer questions and misconceptions
A fixed output outline with internal link targets
Retrieval was just-in-time. The system pulled only the top passages needed for that page, then pruned the rest.
The outcome: faster publishing, fewer rewrites, and more pages earning impressions sooner
They defined “keyword velocity” as how fast a new page begins earning impressions for its target query set. After rollout, the median time to first meaningful impressions dropped, and the cluster expanded faster because editors stopped rewriting basics. Over the quarter, they reported a 300% increase in keyword velocity compared to the prior prompt-only workflow, largely because each draft started with the right facts and the same structure.
Conversion path: turn context engineering into a repeatable growth loop
A good system earns trust because it’s controlled. That’s what decision-makers want: reliability, speed, and an audit trail.
Opt-in landing page blueprint
Promise: “Get the Context Optimization Checklist plus the enterprise guide, From Prompting to Engineering: The Enterprise Guide to Context Management.”
Who it’s for: CTOs, VPs of AI, and SEO content leads who ship AI-assisted pages.
What they get: a one-page checklist, a context pack template, and a rollout plan for a pilot cluster.
Benefits:
Fewer hallucinations on pricing, policy, and feature claims
Lower token spend through pruning and retrieval
More consistent formatting that won’t break CMS workflows
Faster updates when products and policies change
Cleaner scaling across content clusters and agents
Form fields: work email, company, role, primary use case, and one optional question about current stack.
Landing page headline
Stop Publishing Generic AI Fluff: Master the Context Engineering Framework for Instant SEO Results
Supporting subhead suggestions:
Reduce hallucinations by injecting ground truth at inference time.
Scale content safely with reusable context packs and retrieval.
FAQ
What is context engineering, in one sentence?
Context engineering is the process of selecting and organizing the facts, rules, and sources an LLM sees at inference time so it can answer without guessing.
Does context engineering replace prompt engineering?
No. Prompting still matters. Context engineering sets the model’s inputs and constraints so the prompt can work reliably.
Is fine-tuning a better fix for hallucinations?
Fine-tuning can help for stable patterns, but it’s slow and expensive for changing facts. Context engineering is usually the faster path when truth lives in docs, policies, and databases.
How do we handle long documents without dumping them into the prompt?
Use retrieval plus summarization chains. Keep short, cited snippets in the context window, then fetch more only when needed.
Will 128k-plus context windows solve this?
They reduce pressure, but they don’t remove curation work. Long contexts still suffer from attention bias and noise, so pruning and ordering remain critical.
What’s the first pilot worth running?
Pick one revenue-facing cluster with frequent updates (pricing, security, integrations). Build a truth pack, add SERP notes, then measure rewrite rate and time-to-publish.
Conclusion
If your LLM makes things up, don’t treat it like a creativity problem. Treat it like a missing inputs problem. Context engineering fixes that by feeding the right facts, in the right order, at the moment of inference.
Run the 5-point checklist, adopt the prompt structure template, then integrate a shared context library with just-in-time retrieval. Start with one cluster, measure rewrites and accuracy, and ship the pilot. Once the system works, scaling becomes routine instead of stressful.
10 Tools You Need Before Your Blog Becomes Obsolete
If you blog in 2026, you don’t have a writing problem. You have a tool problem.
There are too many tabs, too many prompt tweaks, and too many “finished” drafts that still need a heavy edit. Even when the output is decent, it often comes out bland, repetitive, or slightly off-brand.
That’s why prompt-friendly matters. In plain English, it means tools that reduce typing, reuse your best prompts, keep context across steps, and work where you already write. This AI blogging toolkit 2026 list sticks to that standard.
Below are 10 practical picks, split into browser extensions and standalone platforms. After that, you’ll get a simple workflow to combine them without paying for five tools that do the same thing.
What changed in 2026 that makes today’s AI blogging tools feel different?
The big shift is simple: AI moved from “answer this question” to “finish this workflow.”
Most bloggers now expect multi-step help, not one-off replies. That includes research, outline, draft, edits, formatting, FAQs, and even repurpose copy. As a result, the best tools feel less like chatboxes and more like guided systems with reusable building blocks.
Real-time web access also matters more now. Fresh product changes, pricing pages, policy updates, and new studies show up daily. Tools that can browse can help, because they point you to sources faster. Still, web results can go wrong when the model misreads a page, pulls an outdated cached version, or cites a source that doesn’t say what it claims.
In other words, today’s baseline is higher. Good UX now means the AI sits inside your browser and your CMS, supports prompt packs, and outputs in clean structures (headings, bullets, tables, FAQs). If it can’t do that, it’s just another tab.
From chat to workflows: the rise of multi-step AI agents
A modern “agentic” flow looks like a relay race. You hand off a clear task, then the tool hands you the next piece.
For example, you might run: “Turn this headline into an outline,” then “Draft section 1 with examples,” then “Write a meta description and five internal link ideas.” The best setups also include guardrails, like templates, checklists, and approval steps, so the draft doesn’t wander.
A helpful rule: if the tool can’t show its steps (or let you approve them), it’s harder to trust at scale.
Why prompt-friendly interfaces win (less typing, more consistency)
Prompt fatigue is real. Rewriting the same instructions wastes time, and it also increases inconsistency across posts.
Prompt-friendly tools solve this with features like prompt libraries, slash commands, saved actions, and variables (topic, audience, tone, product name). When you reuse the same “brief prompt” and “section writer prompt,” your posts start to sound like they come from one publisher, not five different bots.
Most importantly, these tools make brand voice easier to repeat. You can store “do” and “don’t” language rules, preferred formatting, and even banned phrases. That turns your best prompts into a system, not a one-time trick.
Top 5 browser extensions that speed up writing, editing, and on-page SEO
Browser tools matter because they live where you work. They sit in Google Docs, WordPress, Webflow, Notion, and search results, so you stop copying text back and forth.
In 2026, the most useful extensions tend to fall into a few buckets: quick research overlays, on-page extraction and summaries, tone and clarity rewrites, and CMS-side helpers for meta text and formatting. The goal is simple, fewer steps between idea and publish.
Perplexity AI (browser): fast research with cited sources you can check
Best for: quick topic research and source discovery. Prompt-friendly feature: follow-up threading and collections, so you can refine questions without resetting context. Risk or limit: citations still need verification, because a link can be irrelevant or misquoted. Quick workflow: ask for “key points with links,” then “opposing views,” then “a short brief with the top sources to read first.”
Treat it like a research assistant that hands you a reading list, not a final authority.
ChatGPT (web) with Projects and memory: reusable prompt packs and voice cues in one place
Best for: turning repeatable instructions into a repeatable process. Prompt-friendly feature: Projects can keep your recurring prompts, style rules, and reference docs together. Risk or limit: privacy, because you shouldn’t paste sensitive data or client secrets without clear rules. Quick setup: create a “Blog Post Project” with brand voice bullets, forbidden phrases, formatting preferences, and a pre-publish checklist.
When your prompts live in one place, your drafts stop drifting.
Grammarly: polishing tone and clarity when the draft feels “AI-ish”
Best for: readability and tone, especially when you want an 8th to 9th grade feel. Prompt-friendly feature: quick rewrites with tone targets, plus consistency checks that nudge you toward simpler phrasing. Risk or limit: it can’t validate facts, so don’t confuse clean writing with true writing. Editing pass example: shorten long sentences, remove filler, swap weak verbs (“is,” “has”) for stronger ones, and reduce jargon.
It’s the tool you open when the post sounds correct but doesn’t sound human.
LanguageTool: lightweight style fixes and consistency across long drafts
Best for: catching repeated words, awkward phrasing, and punctuation issues across many browser writing areas. Prompt-friendly feature: it works quietly in the background, so you don’t stop your flow to fix small issues. Risk or limit: it won’t fix structure problems, like a weak intro or a missing point. Practical tip: run it after your AI draft and before final formatting, because late-stage fixes inside a CMS can get messy.
If you already use another editor, this can still be a solid second pass.
HARPA AI: on-page assistance for summaries, extraction, and quick checks
Best for: working on the page you’re viewing, like summarizing an article or extracting key points. Prompt-friendly feature: saved commands and reusable actions for research pages, product pages, and docs. Risk or limit: auto-summaries can miss nuance or context, so verify against the original text. Quick workflow: open a long source, extract claims and quotes, then generate questions you should answer in your post.
Used well, it cuts research time without turning research into guesswork.
Top 5 standalone platforms for publishing more content without losing quality
Extensions speed up moments. Platforms handle systems.
A good platform becomes your home base for briefs, drafting, repurposing, and team review. These tools also make brand voice easier to apply across many posts, because templates and workflows live alongside your content library.
Jasper: brand voice, campaigns, and templates for repeatable content output
Best for: creators (and teams) producing lots of similar content formats. What makes prompts easier: saved templates and structured workflows, so you don’t start from a blank box each time. How it supports brand voice: brand voice settings can guide tone, vocabulary, and style across outputs. Common pitfall: templates can cause sameness unless you add unique angles, examples, and first-hand notes.
The output improves fast when you feed it real experiences, not just keywords.
Copy.ai: fast repurposing into social posts, email, and ad copy
Best for: turning one blog post into multiple formats without rewriting from scratch. What makes prompts easier: guided workflows that walk you step-by-step, instead of relying on perfect prompting. Brand voice help: you can reuse the same voice cues across channels, so your email doesn’t sound like a different company. Common pitfall: repurposing can introduce new claims, so you must keep facts consistent.
A simple plan: generate a short thread, a LinkedIn post, an email intro, and three hook options, all based on the same approved draft.
Notion AI: one workspace for briefs, drafts, and editorial checklists
Best for: keeping research notes, outlines, and drafts together in one place. What makes prompts easier: reusable page templates with built-in prompts (brief template, outline template, QA checklist). Brand voice help: your “voice rules” can sit on every draft page, so writers don’t forget them. Common pitfall: it’s easy to collect notes forever and publish nothing, so set deadlines.
Notion shines when you add a human review step with comments and approvals.
Surfer: content planning and on-page guidance tied to search intent
Best for: planning sections and covering subtopics readers expect. What makes prompts easier: clear targets you can turn into prompts, like “Write a short section answering X in plain language.” Brand voice help: you can keep the structure while still writing in your own tone and story. Common pitfall: forcing every suggestion can make the post feel robotic.
Use it as a compass, not a rulebook.
WordPress with Jetpack AI Assistant: draft and edit inside the CMS where you publish
Best for: reducing copy-paste steps and speeding up updates inside WordPress. What makes prompts easier: repeatable prompts for titles, excerpts, meta descriptions, and internal link ideas while you edit. Brand voice help: you can keep a consistent format post-to-post, because you work in the final layout. Common pitfall: formatting, links, and claims still need a careful review before publish.
It’s also handy for refreshing older posts, because you can rewrite sections in place.
How to build a cohesive stack that stays affordable, secure, and on-brand
More tools don’t always mean more output. Too many subscriptions often create overlap, extra logins, and inconsistent voice.
A practical stack has five roles: research, drafting home base, editing, optimization, and publishing. Here’s a simple blueprint most independent bloggers can live with.
Stack role
What it should do
Example tools from this list
Research
Find sources fast, keep context, save threads
Perplexity AI, HARPA AI
Drafting home base
Store prompt packs, drafts, and templates
ChatGPT Projects, Notion AI, Jasper
Editing
Improve clarity and tone, reduce “AI sound”
Grammarly, LanguageTool
Optimization
Help cover intent and missing sections
Surfer
Publishing
Format and update in the place you post
WordPress + Jetpack AI Assistant
Takeaway: pick one tool per role first, then upgrade only when you feel real friction.
Pick your “core 3” first, then add tools only when they save real time
Start with Core 3: research, drafting, publishing. If those three feel smooth, everything else becomes optional.
After that, add-ons should earn their spot. Grammar tools are worth it if they cut editing time. SEO guidance helps if it stops you from missing key sections. Repurposing tools pay off if you publish across channels weekly.
To keep it honest, track simple ROI: time saved per post, how often you reuse prompts, and how often you fix avoidable errors. If a tool doesn’t improve those numbers, drop it.
Protect your work and your reputation: permissions, privacy, and human review
Extensions can see a lot. Therefore, treat them like contractors, not trusted staff.
Use least-privilege access, limit extensions to the browsers you need, and separate accounts for client sites. Also, avoid pasting private data, unpublished financials, or customer lists into any AI tool unless you’ve cleared it.
Most importantly, keep a human fact-check step. Save source links, read them, and quote carefully. Add your own experience when you can, because that’s what builds trust over time.
Clean writing is easy to generate. Trust is hard to rebuild.
FAQ (Frequently Asked Questions)
What does “prompt-friendly” mean for bloggers?
It means fewer repeated instructions. The tool should reuse prompts, keep context, and output in a format you can publish with minor edits.
Do I need both a browser extension and a platform?
Usually, yes. Extensions speed up tasks in the moment, while platforms store workflows, templates, and longer projects.
Which tool helps most with brand voice?
Tools with saved prompt packs and voice rules help the most. ChatGPT Projects, Jasper, and Notion templates often work well for this.
How do I reduce hallucinations when researching?
Use tools that provide links, then open and read the sources. Also, ask for opposing views and check dates on studies and announcements.
How can I keep costs under control?
Pick one tool per role first. Then cut overlap, especially between drafting platforms that do similar work.
Conclusion
The best AI blogging toolkit 2026 doesn’t try to replace your judgment. It removes busywork, so you can focus on ideas, proof, and voice.
Start small: choose one extension and one platform. Then build a simple prompt pack (brief, outline, intro, section writer, edit pass) and test it for one week. If it saves time and improves consistency, you’ve found your base.
Want a weekly upgrade without chasing every new tool? Join the Future-Proof Blogging newsletter for one vetted prompt template each week, designed for the tools covered here.
Lead Generation Automation: Workflows to Triple Your Pipeline in 2026
Acquiring new customers has become more straightforward for businesses in 2026. Automated lead generation allows businesses to generate leads more efficiently while achieving faster business growth. Automation is efficient. It helps you reach more people without stress, assess their viability. It also provides better results. For a business, automation provides better information. It also offers better follow-up. You can achieve growth more easily.
That’s why lead generation automation prompts and intent-driven workflows matter more than another tool or another list. Basic automation fires a trigger (form fill, email open) and runs a static sequence. AI-assisted workflows react to signals (pricing visits, comparison searches, repeat sessions, replies) and change the next step in real time.
This gives you a practical workflow plan that can triple pipeline by improving speed-to-lead, lead quality, and follow-up consistency. You’ll also get copy-and-adapt examples of lead generation automation prompts for SEO audit snippets, LinkedIn notes, and short emails. The 2026 outbound landscape is shifting. Don’t get left behind by AI-driven competitors. Learn the specific automation workflows elite executives are using to dominate B2B lead gen now.
Phase 1: Automated lead scoring that catches high-intent SEO prospects in real time
If every lead gets the same follow-up, your pipeline becomes a lottery ticket. In 2026, relevance wins because buying signals show up everywhere: organic searches, product comparisons, return visits, and direct replies. So the first job is to stop treating all leads the same.
A strong model blends fit (are they your ideal customer) and intent (are they acting like a buyer). Keep it simple and fast. Use a 0 to 100 score, computed the moment a signal hits your system through APIs or webhooks. In 2026, sales pipeline automation will dictate that leads are instantly categorized by intent, persona, and fit before a human even sees them. Without this layer of intelligence, your team is simply guessing which leads are worth their time.
Here’s a clean set of thresholds that works across most B2B sales motions:
0 to 39 (Nurture): automate education, retargeting, and light check-ins.
40 to 69 (SDR Review): route to a rep, create a task, start a semi-personal sequence.
70 to 100 (Instant Meeting Push): trigger a high-priority alert and send a meeting-first message.
Your north star metric is speed-to-lead under 5 minutes for high-intent leads. If you want a practical breakdown of why fast routing has become an operational problem (not just an SDR discipline problem), see LeanData’s speed-to-lead guidance: “Emphasizes that immediate, automated, and accurate lead routing is crucial, as 78% of customers buy from the first responder, and qualification chances drop 80% after five minutes.” Key strategies include using automated workflows for instant qualification, implementing “edge priority” to route high-value leads faster, and using “Hold Until” nodes for precise timing.
The second target is conversion quality. Stronger scoring programs often push MQL-to-SQL conversion toward the 39 to 40 percent range because. While the average MQL-to-SQL conversion rate across industries often sits around 13–15%, companies utilizing advanced behavioral scoring and tight sales-marketing alignment can nearly triple this, achieving 39–40% because reps spend time where intent is real, not where volume looks good. High-performing firms also use behavioral data—such as content engagement, website behavior, and product usage—to identify true buying intent.
Build a simple scoring model you can trust (fit points plus intent points)
Start with fit because it’s stable. Then layer intent because it’s the accelerant. A basic model can outperform a complex one if you review it every month and tie changes to closed-won data.
Example point system (adjust to your ICP):
Fit (0 to 50)
Job title match (VP, Director, Head of): +10
Company size in range (50 to 500): +15
Industry match (your top 3 verticals): +10
US target region or territory match: +5
Known tech stack compatibility (if relevant): +10
Intent (0 to 50)
Pricing page visit: +20
Demo or contact page visit: +20
Comparison keyword entry (from SEO or paid search): +15
Reply to an email (even “not now”): +25
Repeat visit within 24 hours: +10
Negative scoring protects your team’s time:
Student or “learning” intent: -20
Competitor domain: -50 (and suppress outreach)
Company far below minimum size: -15 (unless you sell self-serve)
Careers page visits only: -10 (often job seekers)
Don’t guess forever. Each month, take your last 20 closed-won and last 20 closed-lost deals, then ask one question: which signals showed up early? Update weights, then rerun.
Use API triggers to act the moment the score spikes
Scoring only helps when it changes action. In 2026, your workflow should behave like a smoke alarm, not a weekly report.
A clean trigger flow looks like this:
Event arrives (form, chat, Stripe trial, website analytics, ad platform, or webhook).
Log everything in CRM (so forecasting stays real).
Trigger examples that consistently lift pipeline velocity:
Pricing page view + ICP match: mark “Hot,” alert SDR in Slack, send a short meeting-first email.
Comparison page visit: create an SDR task with context, enroll in a 5-touch sequence.
Three sessions in 24 hours: bump priority, add a manager visibility flag.
Dedupe rules prevent chaos. Match on email first, then domain + name, then cookie identity if you have consent. Update the existing record instead of creating a new one, and store the latest “reason for score” as a note.
Phase 2 and 3: A multi-channel stack that runs on autopilot, plus AI personalization that still sounds human
A modern outbound stack fails for one reason: the tools don’t agree on truth. Fix that, and automation starts compounding. Your CRM must be the source of truth, while your workflow tool acts like the wiring harness.
Many teams use Make.com as the glue because it connects channels without heavy engineering. If you want a concrete walkthrough style example of how teams connect forms, tables, and automation scenarios, see a Make.com lead generation build example.
Once the stack is connected, personalization becomes the force multiplier. Still, the goal isn’t to sound like a poet. You’re aiming for “this was meant for me,” in one or two lines, without crossing into creepy.
A practical rule: use only public info and on-site behavior. Never mention sensitive inferences. Don’t reference private data sources in the message. Keep tone calm and direct.
If your automation can’t explain why it chose the next step, it’s not automation, it’s noise.
Wire up LinkedIn, email, and Twitter/X in Make.com without creating a messy stack
Think of your flow in one direction: capture, enrich, score, update CRM, then activate channels. When the order flips, duplicates and conflicting tasks follow.
A clean data flow:
Capture lead or signal (SEO form, LinkedIn lead form export, chat, webinar, inbound email).
Enrich and normalize fields (company name, role, domain, territory).
LinkedIn: auto-create a “connect” task, don’t auto-send DMs at scale.
Email: enroll the contact into a sequence only after dedupe and suppression checks.
Twitter/X: if they mention a pain point or engage with your founder, create a task, then send a human reply.
Slack: alert the owner only for 70+ scores, otherwise you train the team to ignore alerts.
Add guardrails early:
Rate limits per channel (per rep, per domain, per day).
Error handling with retries (if enrichment fails, route to “Needs Data”).
A dead-letter queue (store failed events so nothing disappears).
AI-driven personalization that creates custom SEO audit snippets for every message
Good personalization feels like a sticky note, not a report. Use a repeatable structure so quality stays high even when volume increases.
Template that holds up:
One sentence on what they do.
One specific SEO observation.
One benefit tied to revenue or pipeline.
One clear call to action.
Fast “audit snippet” ideas that AI can generate from a URL and a keyword set:
Title tag and H1 mismatch on a core landing page.
Missing comparison content for a high-intent “X vs Y” term.
Thin location pages that don’t match search intent.
Broken internal links pointing to old product pages.
Weak schema on key pages (product, FAQ, review snippets).
Keep the snippet to 1 to 2 lines. The point is to earn the next click or reply, not to prove you’re smart.
Here are three copy-and-adapt lead generation automation prompts you can use with the same inputs (company URL, ICP, target keyword, and observed behavior). Write them as variables in your workflow tool, then pass them into your AI step.
SEO snippet prompt: Ask for a 2-line observation plus a 1-line benefit, with a confidence note if uncertain.
LinkedIn connect note prompt: Ask for a 200-character note referencing their role and a neutral observation.
90-word email prompt: Ask for a subject line plus a short email using the four-part template above.
If you want more examples to compare styles, Lemlist keeps a public collection of cold outreach prompt templates that can spark variations, especially for tone and formatting.
Phase 4 and 5: The set-and-forget CRM that kills data entry, then scales with low-code
Automation breaks when the CRM becomes a junk drawer. In 2026, your CRM has to behave like a system of record, not a scrapbook. That means lifecycle stages must update from real events, not from rep memory.
The payoff is bigger than cleanliness. When statuses are accurate, leaders can forecast with confidence, managers can coach faster, and SDRs stop spending afternoons doing admin work.
Low-code workflows can also replace a large chunk of repetitive labor. Teams often find 10 to 40 hours a week hiding in tasks like assigning owners, logging touches, chasing no-shows, updating stages, and recycling cold leads. Automate those, and your team gets time back without pushing more spam.
Risk controls matter just as much:
Permissioning (who can trigger outbound).
Audit logs (what changed, when, and why).
Opt-outs and suppression lists synced across tools.
Clear rules for data retention.
For a wider view of how lead gen metrics shift with automation and first-party data, G2 maintains a rolling set of lead generation statistics that can help you sanity-check your internal numbers.
Map automated status updates so every lead and deal stays accurate
Define stages that match observable events. Then make the events move the record automatically.
Recycled: nurture or re-qual path triggered after inactivity.
Disqualified: not ICP, competitor, student, or explicit “no.”
Ownership and next actions should also be automatic:
Route by territory or segment.
Auto-create a task when score hits 40+.
Auto-add a next step when meeting is set (agenda, confirmation, prep research).
Add a stalled timer. For example, if a lead is “Contacted” for 7 days without a reply, trigger either (a) a value-first follow-up, or (b) a manager review when score is high.
Scale safely in 2026: low-code workflows that replace 40 hours a week (without becoming a spam bot)
The fastest way to destroy a brand is to automate without taste. So build three playbooks that create relevance, not volume.
Playbook 1: News trigger workflow When a company raises funding, hires a key leader, or posts a cluster of relevant jobs, trigger a short sequence. Keep message timing tight, and tie it to the event. Avoid exaggeration. The rep should see the source inside the CRM note.
Playbook 2: Multi-channel nurture loop When a prospect engages on LinkedIn or X, sync that signal to email follow-ups. If they like a post, send a short message that continues the topic. If they click an email, create a LinkedIn task, not another email blast.
Playbook 3: Zombie resurrection sequence For stalled opportunities, send value-first content instead of “bumping this.” Examples include a one-page teardown, a competitor comparison page, or a small benchmark. Route positive replies back to the owner, then update stage automatically.
Guardrails that prevent the spam bot trap:
Domain warm-up and sending limits per inbox.
Suppression lists synced across every tool.
Personalization checks (if fields are missing, fall back to a safe generic line).
Sentiment-based monitoring, not just opens (flag negative replies and auto-suppress).
For a few practical prompt patterns that stay simple, Salesforce shares examples of AI prompts for small business sales that translate well to SDR teams when you shorten the output.
FAQ
Can automation really triple pipeline without adding SDRs?
Yes, when the gain comes from conversion and speed, not just volume. Faster routing, cleaner scoring, and consistent follow-up often create a multiplier effect. Still, the workflows must focus on high-intent signals.
What’s the minimum stack to start?
You need four pieces: a CRM, a workflow tool, an email sequencer, and a data enrichment step. Add LinkedIn tasks next. Only then consider extra channels like X, voice drops, or ads.
How do I keep AI personalization from sounding fake?
Keep outputs short, grounded, and specific. Use public info and on-site behavior. Also, require the model to produce a single observation, not a paragraph.
How often should we update the scoring model?
Monthly is a good cadence. Tie changes to closed-won and closed-lost signals, not opinions. If your ICP shifts, update immediately.
What should I measure first?
Track three metrics: speed-to-lead for hot leads, MQL-to-SQL conversion, and meeting set rate per channel. After that, watch pipeline created per rep-hour to prove efficiency gains.
Conclusion
If your team wants more pipeline in 2026, the answer isn’t louder outreach, it’s cleaner automation that reacts to intent. Start small, then let the wins compound.
Here’s a simple 7-day rollout plan: pick one trigger (pricing visit), one scoring threshold (70+), one channel (email), and one CRM status map (New to Scored to Contacted to Meeting Set). After that works, add LinkedIn tasks and a news trigger.
To make this easy to deploy, offer a downloadable workflow library with visual flowcharts of the three sequences (news trigger, multi-channel nurture loop, zombie resurrection) in exchange for an email opt-in. Then keep the next step soft: invite qualified teams to book a consultation to build the system end-to-end.

















 6. VM provisioning request: Trigger chat or catalog request, touches AWS, Azure, or GCP plus CMDB, outcome is faster delivery with standard tags.
6. VM provisioning request: Trigger chat or catalog request, touches AWS, Azure, or GCP plus CMDB, outcome is faster delivery with standard tags.