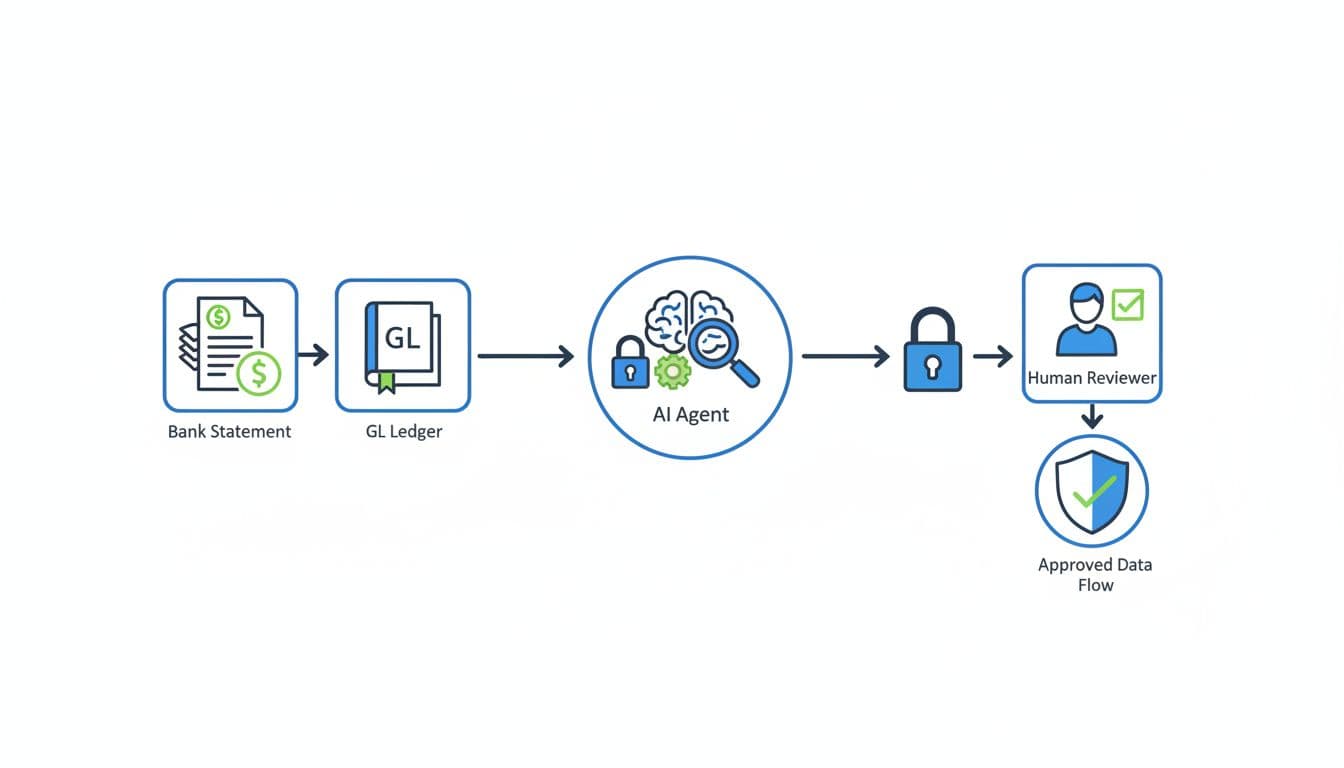
Comprehensive Guide to API Schema Generators
A Senior Software Architect’s Reference for Modern API Development
Table of Contents
- Why API Schema Generation Is Critical
- Code-First vs. Design-First Approaches
- Top Tools by Language & Ecosystem
- Key Evaluation Criteria
- CI/CD Integration Best Practices
1. Why API Schema Generation Is Critical
In a microservices-driven landscape, APIs are the contractual backbone of every distributed system. Without a formal, machine-readable schema, teams operate on assumptions — and assumptions break systems.
Core Benefits
Contractual Consistency
An API schema (most commonly an OpenAPI Specification) acts as a single source of truth shared between frontend developers, backend engineers, QA teams, and technical writers. Schema generators enforce that what is deployed matches what is documented, eliminating “docs drift” — the silent killer of developer experience.
Automated Documentation
Rather than hand-crafting documentation that goes stale the moment a route changes, schema generators like SpringDoc or FastAPI’s built-in engine introspect live code (or vice versa) to produce interactive, always-current documentation rendered by Swagger UI, Redoc, or Scalar.
SDK & Client Code Generation
A valid OpenAPI 3.x schema unlocks automatic generation of typed client libraries across 50+ languages via tools like openapi-generator, Speakeasy, or liblab. This removes manual integration work and guarantees type-safe consumption of your APIs.
Contract Testing & Validation
Schema-driven development enables powerful contract testing. Tools like Prism can mock your API from the spec before a single line of backend code is written, and validators like Spectral can enforce governance rules across every spec in your organization. Source
Parallel Development Velocity
When the schema is defined upfront, frontend, backend, QA, and documentation teams can work in parallel. An agreed-upon OpenAPI spec decouples team dependencies and dramatically reduces time-to-market.
What a Schema Enables
| Downstream Artifact | Tool Examples |
|---|---|
| Interactive API Docs | Swagger UI, Redoc, Scalar |
| Type-safe Client SDKs | openapi-generator, Speakeasy, Fern, liblab |
| Server Stubs | openapi-generator, tsoa |
| Mock Servers | Prism, WireMock, Beeceptor |
| Contract Tests | Dredd, Pact, Schemathesis |
| Governance Linting | Spectral, Vacuum |
2. Code-First vs. Design-First Approaches
This is the foundational architectural decision every API team must make. The two paradigms are fundamentally different in philosophy, tooling, and team workflow. Source
Code-First (Schema-from-Code)
“Build the implementation; derive the contract from it.”
In a code-first workflow, developers write application code using annotations, decorators, or type definitions. A generator then introspects that code to produce an OpenAPI (or GraphQL/gRPC) schema as an artifact.
How It Works (FastAPI Example):
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI(title="Orders API", version="2.1.0")
class Order(BaseModel):
id: int
product: str
quantity: int
price: float
@app.post("/orders", response_model=Order, tags=["Orders"])
async def create_order(order: Order):
"""Create a new order in the system."""
return order
# OpenAPI spec auto-generated at /openapi.json
How It Works (Spring Boot / SpringDoc Example):
@RestController
@RequestMapping("/orders")
@Tag(name = "Orders", description = "Order management endpoints")
public class OrderController {
@Operation(summary = "Create a new order")
@ApiResponse(responseCode = "201", description = "Order created successfully")
@PostMapping
public ResponseEntity<Order> createOrder(@RequestBody @Valid Order order) {
return ResponseEntity.status(HttpStatus.CREATED).body(orderService.save(order));
}
}
✅ Advantages of Code-First
- Speed to prototype: Developers can move quickly without upfront specification overhead.
- Schema accuracy: The spec is derived from running code, so it always reflects the actual implementation state.
- Lower context-switching: Developers stay in their IDE and framework; no external tooling required.
- Ideal for rapid iteration: Well-suited for small teams, startups, and internal tooling where the API consumer is the same team.
- Annotation-driven customization: Rich framework support (FastAPI’s Pydantic, Spring’s
@Schema, Go’sswagcomments) provides fine-grained control.
Disadvantages of Code-First
- Late stakeholder alignment: Non-developer stakeholders (QA, technical writers, frontend) cannot evaluate or test the API until the backend is at least partially implemented.
- Retrofit documentation culture: Documentation becomes an afterthought, often leading to incomplete or inconsistent specs.
- Governance gaps: Without upfront design review, inconsistencies (naming conventions, error schemas, pagination patterns) proliferate across services.
- Breaking changes slip through: Without a defined contract, breaking changes are discovered at runtime rather than at design time.
Design-First (Code-from-Schema)
“Define the contract; generate or build the implementation from it.”
In a design-first workflow, architects and developers collaboratively author an OpenAPI YAML/JSON file (or GraphQL SDL) before any implementation code is written. Code generators then produce server stubs and client SDKs from this spec.
How It Works (OpenAPI YAML → Code):
# openapi.yaml
openapi: 3.1.0
info:
title: Orders API
version: 2.1.0
paths:
/orders:
post:
operationId: createOrder
tags: [Orders]
summary: Create a new order
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/Order'
responses:
'201':
description: Order created
content:
application/json:
schema:
$ref: '#/components/schemas/Order'
components:
schemas:
Order:
type: object
required: [product, quantity, price]
properties:
id:
type: integer
readOnly: true
product:
type: string
quantity:
type: integer
minimum: 1
price:
type: number
format: float
Then generate a Go server stub:
openapi-generator generate \
-i openapi.yaml \
-g go-gin-server \
-o ./server-stub
Advantages of Design-First
- Parallel team execution: Frontend, backend, QA, and docs can all begin work simultaneously from the agreed-upon spec.
- Early governance enforcement: Style guides and naming conventions can be validated by linters (Spectral) before implementation begins.
- API-as-product thinking: Forces teams to think from the consumer’s perspective, resulting in more ergonomic APIs.
- Breaking change prevention: A diff of two spec versions immediately surfaces breaking changes before they reach production.
- Mock servers from day one: Tools like Prism generate a mock server directly from the spec, enabling immediate frontend integration.
Disadvantages of Design-First
- Upfront investment: Writing a complete OpenAPI spec before coding takes discipline and tooling expertise.
- Spec-code synchronization: Teams must maintain discipline to keep the spec and implementation synchronized, or divergence reintroduces the same drift problems.
- Learning curve: Developers unfamiliar with OpenAPI YAML structure face an initial productivity dip.
- Overhead for small/exploratory projects: For internal tools or early-stage prototypes, the design overhead may outweigh the benefits.
Head-to-Head Comparison
| Dimension | Code-First | Design-First |
|---|---|---|
| Initial Speed | ✅ Faster to start | ❌ Slower to start |
| Stakeholder Alignment | ❌ Delayed | ✅ Early & parallel |
| Spec Accuracy | ✅ Always in sync | ⚠️ Requires discipline |
| Governance Enforcement | ❌ Reactive | ✅ Proactive |
| Breaking Change Detection | ❌ At runtime | ✅ At design time |
| Mock Server Availability | ❌ Requires running server | ✅ Immediate via Prism |
| Best For | Startups, internal APIs, rapid prototyping | Platform APIs, public APIs, large teams |
| Tooling Maturity | ✅ Very mature | ✅ Rapidly maturing |
Architect’s Recommendation: For public-facing or platform APIs serving multiple consumers, Design-First is non-negotiable. For internal microservices within a mature team that owns both sides of the contract, Code-First with automated spec generation and Spectral validation in CI/CD delivers the best velocity without sacrificing governance. A hybrid approach — code-first with mandatory Spectral linting and spec diff checks in CI — is increasingly common in enterprise environments.
3. Top Tools by Language & Ecosystem
Python — FastAPI
FastAPI is the gold standard for Python API development with automatic schema generation. It leverages Pydantic v2 for data modeling and introspects routes, types, and annotations to produce a fully compliant OpenAPI 3.1 specification with zero additional configuration.
Key Capabilities:
- Auto-generation: Every route automatically becomes an operation in the OpenAPI document. Every Pydantic model becomes a schema component.
- OpenAPI 3.1 native: FastAPI generates OpenAPI 3.1 by default, enabling full JSON Schema Draft 2020-12 compatibility.
- Customizable metadata: Operation IDs, tags, server URLs, security schemes, and webhooks are all configurable.
- Multiple UIs: Serves Swagger UI at
/docsand Redoc at/redocout of the box. - SDK generation: FastAPI-generated specs are directly consumable by Speakeasy, liblab, and openapi-generator. Source
# Advanced FastAPI customization
from fastapi import FastAPI, Security
from fastapi.security import APIKeyHeader
api_key_header = APIKeyHeader(name="X-API-Key")
app = FastAPI(
title="Orders API",
version="2.1.0",
description="Production-grade order management system",
servers=[
{"url": "https://api.prod.example.com", "description": "Production"},
{"url": "https://api.staging.example.com", "description": "Staging"},
]
)
Companion Tools:
fastapi-versioning— API version managementScalar— modern, feature-rich alternative to Swagger UISchemathesis— property-based API testing from OpenAPI spec
Node.js / TypeScript
tsoa (Code-First, TypeScript-native)
tsoa is a framework-agnostic TypeScript tool that uses TypeScript decorators and type annotations to generate OpenAPI 3.0/3.1 specs and Express/Koa/Hapi route handlers simultaneously. It enforces type safety from model definition through to generated spec. Source
import { Route, Get, Post, Body, Tags } from 'tsoa';
import { Order, CreateOrderRequest } from '../models/order';
@Route('orders')
@Tags('Orders')
export class OrderController {
@Get('{orderId}')
public async getOrder(orderId: number): Promise<Order> {
return orderService.findById(orderId);
}
@Post()
public async createOrder(@Body() body: CreateOrderRequest): Promise<Order> {
return orderService.create(body);
}
}
// Run: tsoa spec-and-routes
// Outputs: openapi.json + routes.ts
swagger-jsdoc (JSDoc annotations)
For teams using plain JavaScript or Express without TypeScript, swagger-jsdoc parses JSDoc comment blocks to construct an OpenAPI spec at runtime or as a build artifact.
Fastify + @fastify/swagger
Fastify’s schema-based routing (using JSON Schema for input validation) makes OpenAPI generation a natural byproduct. @fastify/swagger and @fastify/swagger-ui expose the spec and UI automatically.
Tooling Summary:
| Tool | Approach | OAS Version | TypeScript Support |
|---|---|---|---|
| tsoa | Code-First | 3.0 / 3.1 | ✅ Native |
| swagger-jsdoc | Code-First (JSDoc) | 2.0 / 3.0 | ⚠️ Via TS types |
| @fastify/swagger | Code-First | 3.0 | ✅ With plugins |
| Hono + zod-openapi | Code-First | 3.1 | ✅ Native |
Go
Go’s strength in building high-performance APIs pairs with a growing ecosystem of spec generators.
Swag (swaggo/swag) (Code-First, Comment-based)
Swag converts Go annotations embedded in source code comments into Swagger 2.0 / OpenAPI 3.0 documentation. It integrates with Gin, Echo, Fiber, and the standard net/http package.
// @title Orders API
// @version 2.1.0
// @description Production order management service
// @host api.example.com
// @BasePath /v1
// @Summary Create order
// @Description Create a new order in the system
// @Tags orders
// @Accept json
// @Produce json
// @Param order body CreateOrderRequest true "Order payload"
// @Success 201 {object} Order
// @Router /orders [post]
func CreateOrder(c *gin.Context) { ... }
swag init --generalInfo cmd/main.go --output docs/
# Generates: docs/swagger.json, docs/swagger.yaml, docs/docs.go
oapi-codegen (Design-First, Go-native)
oapi-codegen is the premier design-first tool for Go. It takes an OpenAPI 3.x specification and generates strongly-typed Go interfaces, server boilerplate, and client code for Gin, Echo, Chi, or net/http. It enforces that the implementation satisfies the generated interface at compile time.
oapi-codegen \
--config=oapi-codegen.yaml \
openapi.yaml
go-swagger (Swagger 2.0)
A comprehensive Swagger 2.0 implementation for Go with bidirectional generation (spec-to-code and code-to-spec). Better suited for teams not yet migrated to OpenAPI 3.x.
Go Tooling Decision Matrix:
| Scenario | Recommended Tool |
|---|---|
| Code-first with Gin/Echo | swag |
| Design-first with OpenAPI 3.x | oapi-codegen |
| Legacy Swagger 2.0 integration | go-swagger |
| Design-first with full federation | oapi-codegen + Buf |
Java — Spring Ecosystem
SpringDoc OpenAPI (Code-First)
SpringDoc is the de facto standard for OpenAPI 3.x generation in Spring Boot applications. It replaced the aging springfox library and offers seamless auto-configuration that introspects Spring MVC controllers, Spring Security, and Spring Data REST endpoints. Source
<!-- pom.xml -->
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>2.8.x</version>
</dependency>
@Configuration
@OpenAPIDefinition(
info = @Info(
title = "Orders API",
version = "2.1.0",
description = "Production order management service"
),
security = @SecurityRequirement(name = "bearerAuth")
)
@SecurityScheme(
name = "bearerAuth",
type = SecuritySchemeType.HTTP,
scheme = "bearer",
bearerFormat = "JWT"
)
public class OpenApiConfig {}
With SpringDoc, the spec is served at /v3/api-docs and Swagger UI at /swagger-ui.html automatically. It supports OpenAPI 3.0 natively, with community efforts pushing toward 3.1.
Key features:
- Spring Security integration for documenting auth flows
- Support for Kotlin coroutines and reactive WebFlux APIs
@Schema,@Parameter,@Operation,@ApiResponseannotation support- JavaDoc integration (via
springdoc-openapi-javadocprocessor) - Maven/Gradle plugin for spec generation at build time

GraphQL Tools
GraphQL has its own distinct schema paradigm using the Schema Definition Language (SDL). The tooling ecosystem divides into schema-first (write SDL, generate resolvers) and code-first (write resolvers, generate SDL).
GraphQL Code Generator (Universal — The Guild)
The most widely adopted GraphQL codegen tool. Given a GraphQL schema (SDL), it generates TypeScript types, React hooks, Angular services, and resolver signatures. Essential for type-safe end-to-end development.
npm install -D @graphql-codegen/cli @graphql-codegen/typescript
# codegen.yaml
schema: "http://localhost:4000/graphql"
generates:
src/generated/types.ts:
plugins:
- typescript
- typescript-operations
- typescript-react-apollo
Pothos (formerly GiraphQL) (Code-First, TypeScript)
Pothos is the modern choice for code-first GraphQL in TypeScript. It uses a plugin architecture and TypeScript inference to generate type-safe GraphQL schemas without any code generation step — the schema is the types.
import SchemaBuilder from '@pothos/core';
const builder = new SchemaBuilder<{
Objects: { Order: Order };
}>();
builder.objectType('Order', {
fields: (t) => ({
id: t.exposeID('id'),
product: t.exposeString('product'),
quantity: t.exposeInt('quantity'),
price: t.exposeFloat('price'),
}),
});
TypeGraphQL (Code-First, Decorator-based)
TypeGraphQL uses TypeScript decorators (@ObjectType, @Field, @Resolver) to define the schema alongside class definitions, similar to SpringDoc’s annotation approach. Well-established with a large ecosystem.
Apollo Studio (Design-First, Enterprise)
Apollo Studio provides a collaborative environment for schema design, registry, federation management, and breaking change detection across federated GraphQL supergraphs.
| Tool | Paradigm | Best For |
|---|---|---|
| GraphQL Code Generator | Schema-First (codegen) | TypeScript type safety from existing SDL |
| Pothos | Code-First | Modern TS-native schema building |
| TypeGraphQL | Code-First | Decorator-heavy OOP style |
| Nexus | Code-First | Programmatic, functional schema |
| Apollo Studio | Design-First + Registry | Enterprise federated GraphQL |
| Strawberry (Python) | Code-First | Python GraphQL with type hints |
Cross-Language & Universal Tools
| Tool | Description | Best Use Case |
|---|---|---|
| OpenAPI Generator | Open-source; generates clients, servers, and docs for 50+ languages | Broad language coverage, no-cost SDK generation |
| Speakeasy | AI-powered SDK generation with GitHub integration | Production-quality multi-language SDKs |
| Fern | Schema-first approach with integrated docs site generation | Clean SDKs + documentation websites |
| liblab | Enterprise SDK lifecycle management with SOC 2 compliance | Enterprise SDK generation and maintenance |
| Stoplight Studio | Visual OpenAPI designer with linting and mocking | Design-first teams; non-developer stakeholders |
| Spectral | JSON/YAML linter for OpenAPI, AsyncAPI, JSON Schema | API governance and CI/CD linting |
4. Key Evaluation Criteria
When selecting an API schema generator for your stack, assess each tool against the following dimensions:
Criteria 1: OpenAPI Version Support
The OpenAPI specification version determines which features your schema can express and which downstream tooling it’s compatible with.
| Feature | OpenAPI 2.0 (Swagger) | OpenAPI 3.0.x | OpenAPI 3.1.x |
|---|---|---|---|
| Full JSON Schema support | ❌ | ❌ Partial | ✅ Draft 2020-12 |
| Webhooks | ❌ | ❌ | ✅ Native |
| Nullable fields | ❌ | nullable: true | Type union ["string","null"] |
$ref with siblings | ❌ | ❌ | ✅ |
$schema declaration | ❌ | ❌ | ✅ |
| Examples in schemas | Limited | Limited | ✅ First-class |
| Tooling maturity | ✅ Widest | ✅ Very wide | ⚠️ Growing fast |
Recommendation: Prefer tools that support OpenAPI 3.1 for new projects. For teams with mature 3.0 specs, verify critical downstream tooling (SDK generators, documentation renderers) supports 3.1 before migrating. Source
Criteria 2: Automated SDK & Client Generation
Evaluate whether the tool’s output is clean enough for direct SDK generation without manual remediation:
- Operation ID uniqueness and readability: Poorly named
operationIdvalues (ordersPostvscreateOrder) produce unusable SDK method names. - Schema component reuse: Tools that inline all schemas vs. using
$refcomponents produce bloated, non-navigable specs. - Security scheme accuracy: Authentication flows must be correctly modeled for SDKs to generate usable auth helpers.
- Response schema completeness: All status codes (200, 201, 400, 401, 422, 500) should have documented response schemas for robust error handling in SDKs.
SDK Generator Comparison:
| Generator | Languages | Quality | Enterprise | Cost |
|---|---|---|---|---|
| openapi-generator | 50+ | Variable | ❌ | Free |
| Speakeasy | 8+ | ✅ High | ⚠️ Partial | Paid |
| Fern | 6+ | ✅ High | ⚠️ Partial | Freemium |
| liblab | 6+ (TypeScript, Python, Java, Go, C#, PHP) | ✅ High | ✅ SOC 2 | Paid |
| Stainless | Limited | ✅ High | ⚠️ | Paid |
Criteria 3: Validation & Linting Capabilities
A schema generator that produces an invalid or incomplete spec is worse than no generator at all — it gives a false sense of security.
Validation levels to evaluate:
- Syntactic validity: Does the generated spec conform to the OpenAPI JSON Schema?
- Semantic validity: Are all
$refreferences resolvable? Are required fields present? - Style governance: Are naming conventions (camelCase, kebab-case), required fields (descriptions, examples), and pagination patterns enforced?
- Breaking change detection: Does the tool or its CI companion detect changes that would break existing consumers?
Key validation tools to integrate:
# Spectral: OpenAPI linting with custom rulesets
npx @stoplight/spectral-cli lint openapi.yaml --ruleset .spectral.yaml
# oasdiff: Detect breaking changes between spec versions
oasdiff breaking base-openapi.yaml new-openapi.yaml
# Redocly: Full validation and bundling
redocly lint openapi.yaml
Criteria 4: Framework & Language Integration Depth
Superficial integration produces incomplete schemas. Deep integration means:
- Automatic route discovery: All endpoints detected, not just manually annotated ones.
- Pydantic/TypeScript/Java type reflection: Complex generic types, unions, and discriminated unions are correctly translated to JSON Schema.
- Middleware awareness: Authentication, rate limiting headers, and standard error responses derived from framework middleware are included.
- Versioning support: Native support for API versioning strategies (path versioning, header versioning).
Criteria 5: CI/CD & Automation Readiness
- Does the tool offer a CLI for use in automated pipelines?
- Does it support exit code semantics (non-zero exit on validation failure)?
- Are there official GitHub Actions / GitLab CI integrations?
- Can it diff two spec versions and fail the pipeline on breaking changes?
- Does it produce artifacts (JSON/YAML files) that can be published to a registry or documentation platform?
Criteria 6: Community, Maintenance & Licensing
| Factor | What to Check |
|---|---|
| Maintenance cadence | Last commit date, release frequency, open issues response time |
| Community size | GitHub stars, contributors, Stack Overflow activity |
| License | MIT/Apache 2.0 for open-source use; check commercial restrictions |
| Vendor lock-in | Can the output be used independently of the tool vendor? |
| Enterprise support | Paid SLAs, security audits, compliance certifications |
5. CI/CD Integration Best Practices
Integrating API schema generation into your CI/CD pipeline transforms schema management from a manual, error-prone task into an automated quality gate.
The API Schema CI/CD Pipeline Architecture
┌─────────────────────────────────────────────────────────┐
│ Developer Commits │
└─────────────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ Stage 1: Schema Generation │
│ • Generate OpenAPI spec from code (or validate │
│ design-first spec against implementation) │
│ • Artifact: openapi.yaml │
└─────────────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ Stage 2: Linting & Governance Validation │
│ • Spectral lint with custom ruleset │
│ • Fail on: missing descriptions, invalid formats, │
│ undocumented error responses, naming violations │
└─────────────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ Stage 3: Breaking Change Detection │
│ • Diff against published spec (oasdiff / openapi-diff) │
│ • Fail PR if breaking changes detected on main branch │
│ • Require manual override + changelog for breaks │
└─────────────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ Stage 4: Contract Testing │
│ • Schemathesis: property-based testing against spec │
│ • Prism mock validation │
│ • Dredd: integration tests from spec examples │
└─────────────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ Stage 5: Artifact Publishing │
│ • Publish spec to API registry (Stoplight, SwaggerHub) │
│ • Trigger SDK regeneration (openapi-generator/Fern) │
│ • Deploy updated documentation (Redoc, Mintlify) │
└─────────────────────────────────────────────────────────┘
GitHub Actions Example: Full API Schema Pipeline
# .github/workflows/api-schema.yml
name: API Schema Validation & Publishing
on:
push:
branches: [main, develop]
pull_request:
paths:
- 'src/**'
- 'openapi.yaml'
jobs:
validate-schema:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0 # Required for oasdiff comparison
# Stage 1: Generate spec (code-first example)
- name: Generate OpenAPI Spec
run: |
pip install fastapi[all]
python scripts/generate_openapi.py > openapi.yaml
# Stage 2: Lint with Spectral
- name: Lint with Spectral
uses: stoplightio/spectral-action@latest
with:
file_glob: 'openapi.yaml'
spectral_ruleset: '.spectral.yaml'
# Stage 3: Detect breaking changes (on PRs to main)
- name: Check for Breaking Changes
if: github.base_ref == 'main'
run: |
docker run --rm \
-v $(pwd):/repo \
tufin/oasdiff breaking \
/repo/openapi-baseline.yaml \
/repo/openapi.yaml \
--fail-on ERR
# Stage 4: Contract testing with Schemathesis
- name: Run Contract Tests
run: |
pip install schemathesis
schemathesis run openapi.yaml \
--url http://localhost:8000 \
--checks all \
--stateful=links
# Stage 5: Publish to registry on main
- name: Publish Spec to Registry
if: github.ref == 'refs/heads/main'
run: |
npx @redocly/cli push \
openapi.yaml \
@my-org/orders-api@latest
Spectral Custom Ruleset for API Governance
# .spectral.yaml
extends: ["spectral:oas"]
rules:
# All operations must have descriptions
operation-description-required:
description: "Operations must have a non-empty description"
given: "$.paths[*][*]"
severity: error
then:
field: description
function: truthy
# All schemas must have examples
schema-example-required:
description: "Schema properties should have examples"
given: "$.components.schemas[*].properties[*]"
severity: warn
then:
field: example
function: truthy
# Enforce kebab-case for path segments
path-kebab-case:
description: "Path segments must use kebab-case"
given: "$.paths[*]~"
severity: warn
then:
function: pattern
functionOptions:
match: "^(\/[a-z0-9-]+)*\/?$"
# 4xx and 5xx responses must be documented
error-responses-documented:
description: "APIs must document 4xx error responses"
given: "$.paths[*][*].responses"
severity: error
then:
function: schema
functionOptions:
schema:
required: ["400", "401", "422", "500"]

Best Practices Summary
Schema Generation
- Automate spec generation as part of the build step, not a manual developer task.
- Store the generated
openapi.yamlas a versioned artifact in your artifact registry. - Use semantic versioning for your API spec and tie spec versions to API releases.
Validation & Governance
- Implement a tiered Spectral ruleset:
errorlevel for structural problems,warnfor style violations. Fail CI only on errors. - Maintain a “golden” baseline spec in source control for breaking change detection.
- Never allow merges to
mainthat introduce undocumented breaking changes without a formal deprecation entry.
SDK Generation
- Trigger SDK regeneration automatically on every merge to
mainthat changes the spec. - Pin SDK consumers to specific spec versions and use automated dependency update PRs (Renovate/Dependabot) to control upgrade cadence.
- Validate generated SDK code compiles and passes smoke tests before publishing to package registries.
Documentation
- Publish updated API documentation automatically on every spec version release.
- Use conditional environment-based server URLs (
x-environmentextensions) to prevent test environments from appearing in public documentation. - Include request and response examples in every operation — these are the most valuable developer experience artifact in your spec.
Observability
- Tag API operations with owner teams (
x-api-owner) so schema governance alerts route to the right team. - Monitor schema validity over time in a dashboard. Schema debt accumulates silently.
Final Recommendations by Team Profile
| Team Profile | Recommended Stack |
|---|---|
| Python / Startup | FastAPI + Pydantic + Schemathesis + openapi-generator |
| Node.js / TypeScript | tsoa + Spectral + Fern SDKs |
| Go / Microservices | oapi-codegen (design-first) + Spectral + oasdiff |
| Java / Enterprise | SpringDoc + Redocly + liblab for SDKs |
| GraphQL / Full-stack TS | Pothos + GraphQL Code Generator + Apollo Studio |
| Multi-language Platform API | Stoplight Studio + Spectral + Speakeasy/liblab |
| Internal Services | FastAPI or tsoa (code-first) + Spectral lint in CI |
This guide reflects the state of the ecosystem as of early 2026. The API tooling landscape evolves rapidly — always validate tool capabilities against your specific framework version before adoption.











 6. VM provisioning request: Trigger chat or catalog request, touches AWS, Azure, or GCP plus CMDB, outcome is faster delivery with standard tags.
6. VM provisioning request: Trigger chat or catalog request, touches AWS, Azure, or GCP plus CMDB, outcome is faster delivery with standard tags.